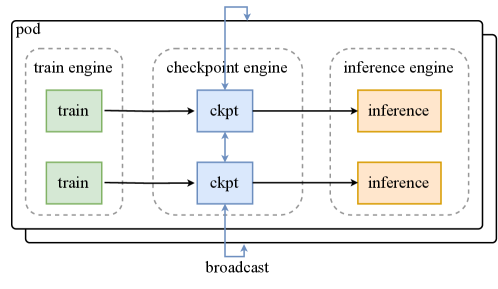
## Diagram: System Architecture for Training and Inference Workflow
### Overview
The diagram illustrates a distributed system architecture with three primary components: **train engine**, **checkpoint engine**, and **inference engine**. These components are interconnected via labeled blocks ("train," "ckpt," "inference") and directional arrows, with a "broadcast" mechanism linking the checkpoint engine to the inference engine. The system is encapsulated within a "pod" boundary.
### Components/Axes
- **Pod**: Outer boundary enclosing all components.
- **Train Engine**: Contains two green blocks labeled "train," connected to the checkpoint engine.
- **Checkpoint Engine**: Contains two blue blocks labeled "ckpt," acting as intermediaries between train and inference engines.
- **Inference Engine**: Contains two orange blocks labeled "inference," receiving input from the checkpoint engine.
- **Broadcast**: A bidirectional arrow connecting the checkpoint engine to the inference engine, indicating data sharing.
- **Legend**: Located at the bottom-right corner, mapping colors to labels:
- Green: "train"
- Blue: "ckpt"
- Orange: "inference"
### Detailed Analysis
1. **Train Engine**:
- Two parallel "train" blocks (green) process data and send outputs to the checkpoint engine.
- No explicit input source is shown; assumed to receive raw data externally.
2. **Checkpoint Engine**:
- Two "ckpt" blocks (blue) receive data from the train engine.
- Outputs are split:
- One path connects to the inference engine.
- Another path loops back to the train engine (dashed line), suggesting iterative training or feedback.
3. **Inference Engine**:
- Two "inference" blocks (orange) receive data from the checkpoint engine.
- No explicit output is shown; assumed to produce results externally.
4. **Broadcast Mechanism**:
- A bidirectional arrow links the checkpoint engine to the inference engine, enabling shared access to checkpoint data.
### Key Observations
- **Parallelism**: Each engine contains two identical blocks, implying parallel processing or redundancy.
- **Feedback Loop**: The dashed line from "ckpt" to "train" suggests iterative refinement of training data.
- **Shared Checkpoints**: The broadcast arrow indicates checkpoint data is reused across inference tasks.
### Interpretation
This architecture optimizes resource efficiency by:
1. **Decoupling Training and Inference**: Separating compute-heavy training (train engine) from real-time inference (inference engine).
2. **Leveraging Checkpoints**: The checkpoint engine acts as a mediator, storing intermediate states (ckpt) for reuse, reducing redundant computations.
3. **Scalability**: Parallel blocks in each engine allow horizontal scaling (e.g., distributed training/inference).
4. **Iterative Improvement**: The feedback loop from checkpoints to training enables model refinement using inference-derived insights.
The system prioritizes modularity and reusability, common in machine learning pipelines where training and inference are resource-intensive and require coordination.