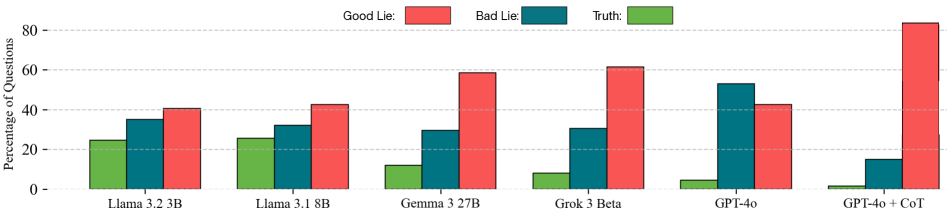
## Bar Chart: Percentage of Questions Answered as Good Lie, Bad Lie, and Truth by Different Models
### Overview
The image is a bar chart comparing the performance of different language models in answering questions, categorized as "Good Lie," "Bad Lie," and "Truth." The y-axis represents the percentage of questions, and the x-axis represents the different language models. The chart uses color-coded bars to represent each category: red for "Good Lie," teal for "Bad Lie," and green for "Truth."
### Components/Axes
* **Y-axis:** "Percentage of Questions," ranging from 0 to 80, with gridlines at intervals of 20.
* **X-axis:** Language models: Llama 3.2 3B, Llama 3.1 8B, Gemma 3 27B, Grok 3 Beta, GPT-4o, GPT-4o + CoT.
* **Legend:** Located at the top of the chart.
* Good Lie: Red
* Bad Lie: Teal
* Truth: Green
### Detailed Analysis
Here's a breakdown of the data for each language model:
* **Llama 3.2 3B:**
* Truth (Green): Approximately 24%
* Bad Lie (Teal): Approximately 36%
* Good Lie (Red): Approximately 41%
* **Llama 3.1 8B:**
* Truth (Green): Approximately 25%
* Bad Lie (Teal): Approximately 33%
* Good Lie (Red): Approximately 43%
* **Gemma 3 27B:**
* Truth (Green): Approximately 12%
* Bad Lie (Teal): Approximately 29%
* Good Lie (Red): Approximately 57%
* **Grok 3 Beta:**
* Truth (Green): Approximately 8%
* Bad Lie (Teal): Approximately 31%
* Good Lie (Red): Approximately 61%
* **GPT-4o:**
* Truth (Green): Approximately 5%
* Bad Lie (Teal): Approximately 54%
* Good Lie (Red): Approximately 42%
* **GPT-4o + CoT:**
* Truth (Green): Approximately 1%
* Bad Lie (Teal): Approximately 15%
* Good Lie (Red): Approximately 83%
### Key Observations
* The "GPT-4o + CoT" model has a significantly higher percentage of "Good Lie" answers compared to other models.
* The "GPT-4o" model has the highest percentage of "Bad Lie" answers.
* The "Truth" percentage is generally low across all models, with "GPT-4o + CoT" being the lowest.
* Llama 3.2 3B and Llama 3.1 8B have similar distributions of "Truth," "Bad Lie," and "Good Lie" answers.
* Grok 3 Beta has a very low "Truth" percentage and a high "Good Lie" percentage.
### Interpretation
The chart suggests that different language models have varying tendencies to provide "Good Lies," "Bad Lies," and "Truthful" answers. The "GPT-4o + CoT" model appears to be heavily biased towards "Good Lies," while the "GPT-4o" model leans towards "Bad Lies." The low "Truth" percentages across all models indicate a potential challenge in ensuring the reliability and accuracy of these models' responses. The Chain of Thought (CoT) prompting technique seems to drastically alter the behavior of GPT-4o, shifting it from a higher "Bad Lie" rate to a very high "Good Lie" rate. This highlights the sensitivity of these models to prompting strategies and the need for careful evaluation and calibration.