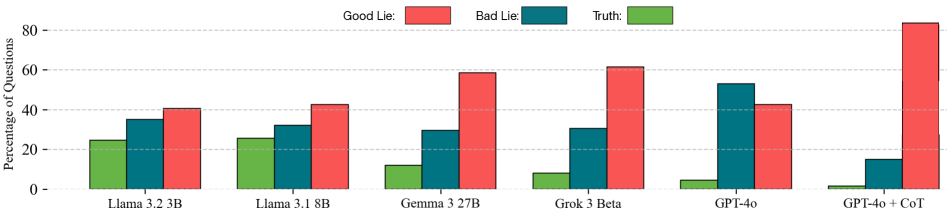
## Bar Chart: Percentage of Questions Answered Correctly by Model Type
### Overview
The chart compares the performance of six AI models (Llama 3.2 3B, Llama 3.1 8B, Gemma 3 27B, Grok 3 Beta, GPT-4o, and GPT-4o + CoT) across three question types: "Good Lie," "Bad Lie," and "Truth." Performance is measured as the percentage of questions answered correctly, with distinct color-coded bars for each category.
### Components/Axes
- **X-axis**: Model types (Llama 3.2 3B, Llama 3.1 8B, Gemma 3 27B, Grok 3 Beta, GPT-4o, GPT-4o + CoT).
- **Y-axis**: Percentage of questions (0–80%).
- **Legend**:
- Red: Good Lie
- Teal: Bad Lie
- Green: Truth
- **Bar Colors**: Each model has three bars (red, teal, green) aligned vertically.
### Detailed Analysis
1. **Llama 3.2 3B**:
- Good Lie: ~40% (red)
- Bad Lie: ~35% (teal)
- Truth: ~25% (green)
2. **Llama 3.1 8B**:
- Good Lie: ~42% (red)
- Bad Lie: ~32% (teal)
- Truth: ~26% (green)
3. **Gemma 3 27B**:
- Good Lie: ~58% (red)
- Bad Lie: ~30% (teal)
- Truth: ~12% (green)
4. **Grok 3 Beta**:
- Good Lie: ~61% (red)
- Bad Lie: ~31% (teal)
- Truth: ~8% (green)
5. **GPT-4o**:
- Good Lie: ~42% (red)
- Bad Lie: ~53% (teal) *(highest Bad Lie performance)*
- Truth: ~4% (green)
6. **GPT-4o + CoT**:
- Good Lie: ~83% (red) *(highest Good Lie performance)*
- Bad Lie: ~15% (teal)
- Truth: ~1% (green) *(lowest Truth performance)*
### Key Observations
- **Good Lie Dominance**: Most models perform best on "Good Lie" questions, with GPT-4o + CoT achieving the highest (83%).
- **Bad Lie Anomaly**: GPT-4o uniquely outperforms others on "Bad Lie" (53%), suggesting potential overconfidence in generating falsehoods.
- **Truth Struggles**: All models perform poorly on "Truth" questions, with GPT-4o + CoT at a critical low (1%).
- **CoT Impact**: Adding Chain of Thought (CoT) to GPT-4o improves Good Lie performance but worsens Truth accuracy, indicating reasoning steps may not enhance factual correctness.
### Interpretation
The data highlights a critical trade-off: models excel at generating plausible lies ("Good Lie" and "Bad Lie") but struggle with factual accuracy ("Truth"). The dramatic drop in Truth performance for GPT-4o + CoT suggests that reasoning frameworks (CoT) may inadvertently prioritize coherence over factual rigor. GPT-4o’s high Bad Lie score raises concerns about its reliability in adversarial contexts. These trends underscore the challenge of aligning AI systems with truthful, context-aware responses, particularly in high-stakes applications.