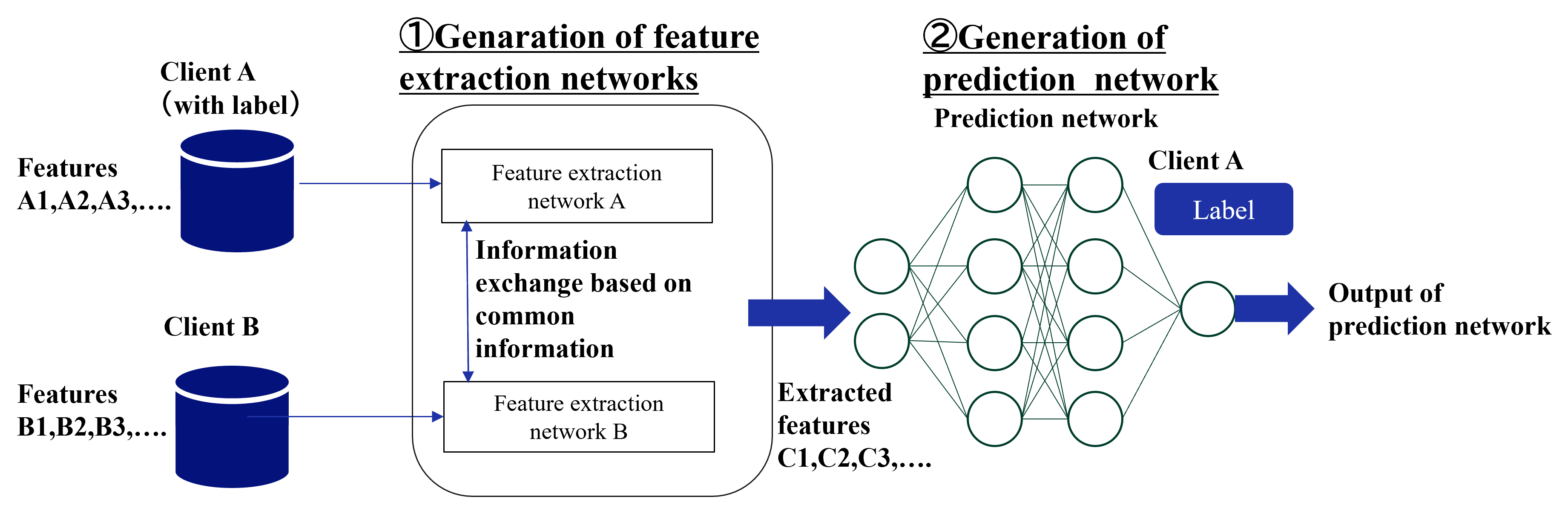
## Diagram: System Architecture for Feature Extraction and Prediction
### Overview
This diagram illustrates a two-stage machine learning architecture. The process begins with the extraction of features from two distinct data sources (Client A and Client B) using a collaborative network structure. These extracted features are then fed into a secondary prediction network to produce a final output.
### Components/Flow
The diagram is organized into two primary stages, flowing from left to right:
**1. Left Region: Data Input**
* **Client A (with label):** Represented by a dark blue cylinder icon.
* Associated text: "Features A1, A2, A3, ..."
* **Client B:** Represented by a dark blue cylinder icon.
* Associated text: "Features B1, B2, B3, ..."
**2. Center Region: Feature Extraction (Stage 1)**
* **Header:** "①Generation of feature extraction networks"
* **Internal Components:**
* "Feature extraction network A" (Top box)
* "Feature extraction network B" (Bottom box)
* **Interaction:** A vertical bidirectional arrow connects the two networks, labeled: "Information exchange based on common information."
**3. Right Region: Prediction (Stage 2)**
* **Header:** "②Generation of prediction network"
* **Sub-header:** "Prediction network"
* **Input:** A large blue arrow points from the Feature Extraction stage to the Prediction Network, labeled "Extracted features C1, C2, C3, ...".
* **Neural Network Visualization:** A graph consisting of nodes (circles) and connecting lines, arranged in four layers (input layer, two hidden layers, output layer).
* **Additional Input:** A blue box labeled "Client A" with a sub-label "Label" feeds into the prediction network.
* **Final Output:** A blue arrow pointing to the right, labeled "Output of prediction network."
### Detailed Analysis
* **Stage 1 (Feature Extraction):** The system takes raw features from two clients (A and B). These inputs are processed by separate networks. The critical design element here is the "Information exchange" mechanism, which suggests that the networks are not trained in isolation but are designed to share knowledge or align representations based on shared/common information.
* **Stage 2 (Prediction):** The output of the first stage (the "Extracted features C1, C2, C3...") serves as the input for the prediction network. This network appears to be a standard feed-forward neural network.
* **Integration:** The prediction network integrates the extracted features with specific "Label" data associated with "Client A." This implies that the prediction task is likely supervised, using Client A's labels as the ground truth or target variable.
### Key Observations
* **Collaborative Learning:** The bidirectional arrow between the two feature extraction networks is the most significant architectural feature, indicating a multi-view or federated learning approach where the two clients benefit from each other's data distributions.
* **Asymmetry:** While both clients contribute to the feature extraction stage, only Client A is explicitly shown providing a "Label" to the prediction network, suggesting Client A may be the primary domain or the source of the target variable.
### Interpretation
This diagram depicts a **Multi-View or Federated Learning architecture**.
The logic suggests that the system aims to solve a prediction problem where data is distributed across two clients (A and B). Because the clients might have different feature spaces (A1... vs B1...), the system uses a collaborative feature extraction process to align these disparate inputs into a unified representation ("Extracted features C1, C2, C3...").
By exchanging information during the extraction phase, the system likely creates a more robust feature set than if each client were processed independently. The final prediction network then consumes these refined features, combined with the specific labels from Client A, to perform the final inference. This is a common pattern in scenarios where one client has labeled data (Client A) and another client has unlabeled or auxiliary data (Client B) that can help improve the model's performance.