## Line Chart: Performance Scaling with Number of Processors
### Overview
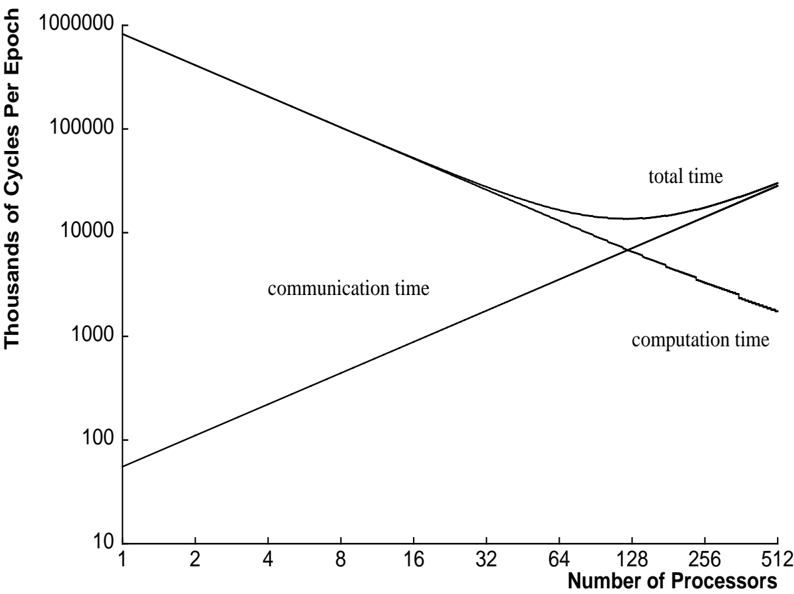
The image is a line chart illustrating the relationship between the number of processors used and the thousands of cycles per epoch for computation time, communication time, and total time. The x-axis represents the number of processors (ranging from 1 to 512), and the y-axis represents the thousands of cycles per epoch (ranging from 10 to 1,000,000) on a logarithmic scale.
### Components/Axes
* **X-axis:** Number of Processors (scale: 1, 2, 4, 8, 16, 32, 64, 128, 256, 512)
* **Y-axis:** Thousands of Cycles Per Epoch (logarithmic scale: 10, 100, 1000, 10000, 100000, 1000000)
* **Data Series:**
* **Computation Time:** A line that generally decreases as the number of processors increases.
* **Communication Time:** A line that increases as the number of processors increases.
* **Total Time:** A line that initially decreases, reaches a minimum, and then increases as the number of processors increases.
### Detailed Analysis
* **Computation Time:**
* At 1 processor, the computation time is approximately 1,000,000 cycles per epoch.
* At 64 processors, the computation time is approximately 10,000 cycles per epoch.
* At 512 processors, the computation time is approximately 1,000 cycles per epoch.
* The line shows a decreasing trend, indicating that computation time decreases as the number of processors increases. The rate of decrease slows down as the number of processors increases.
* **Communication Time:**
* At 1 processor, the communication time is approximately 50 cycles per epoch.
* At 64 processors, the communication time is approximately 5,000 cycles per epoch.
* At 512 processors, the communication time is approximately 20,000 cycles per epoch.
* The line shows an increasing trend, indicating that communication time increases as the number of processors increases.
* **Total Time:**
* At 1 processor, the total time is approximately 1,000,000 cycles per epoch.
* The total time decreases until approximately 64 processors, where it reaches a minimum of approximately 10,000 cycles per epoch.
* After 64 processors, the total time increases to approximately 20,000 cycles per epoch at 512 processors.
* The line shows a U-shaped trend, indicating that total time initially decreases with more processors, but eventually increases due to communication overhead.
### Key Observations
* Computation time decreases with an increasing number of processors, suggesting parallelization benefits.
* Communication time increases with an increasing number of processors, indicating overhead associated with inter-processor communication.
* Total time initially decreases, indicating that the benefits of parallelization outweigh the communication overhead. However, beyond a certain number of processors (around 64), the communication overhead becomes dominant, causing the total time to increase.
### Interpretation
The chart demonstrates the trade-off between computation time and communication time when using multiple processors. Initially, adding more processors reduces the computation time significantly, leading to a decrease in total time. However, as the number of processors increases, the communication overhead becomes more significant, eventually outweighing the benefits of parallelization and causing the total time to increase. The optimal number of processors, in this case, appears to be around 64, where the total time is minimized. This suggests that there is a point of diminishing returns when adding more processors, and that careful consideration must be given to the communication overhead when designing parallel algorithms.