## Line Graphs and Bar Charts: Training Dynamics Across Protocols
### Overview
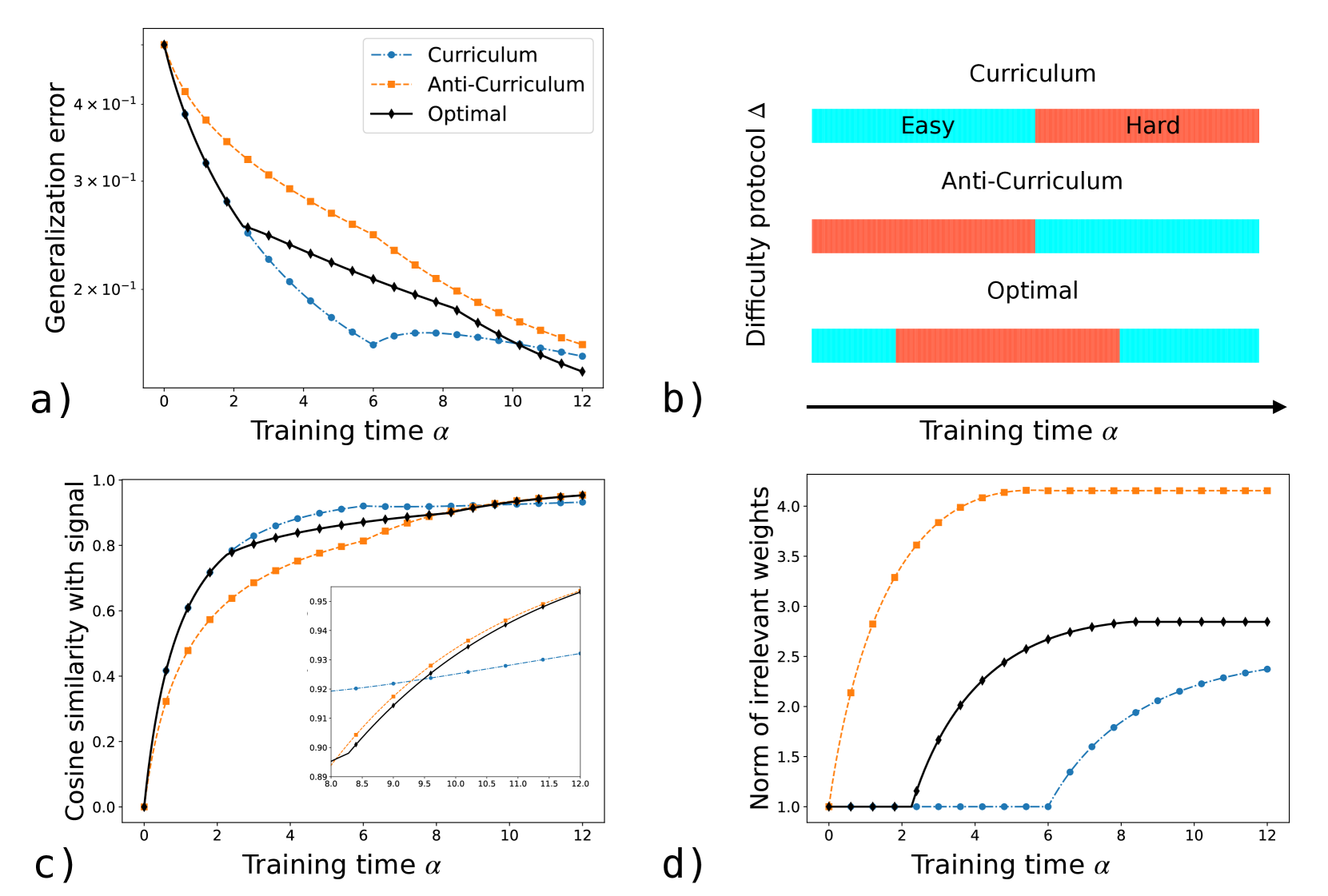
The image contains four panels (a-d) comparing three training protocols (Curriculum, Anti-Curriculum, Optimal) across metrics: generalization error, difficulty protocol distribution, cosine similarity with signal, and norm of irrelevant weights. All graphs plot metrics against training time (α) from 0 to 12.
---
### Components/Axes
#### Panel a) Generalization Error
- **X-axis**: Training time (α), linear scale 0–12.
- **Y-axis**: Generalization error (log scale, 2×10⁻¹ to 4×10⁻¹).
- **Legend**:
- Blue (solid): Curriculum
- Orange (dashed): Anti-Curriculum
- Black (dotted): Optimal
#### Panel b) Difficulty Protocol
- **X-axis**: Training time (α), linear scale 0–12.
- **Y-axis**: Difficulty protocol (categorical: Easy [blue], Hard [red]).
- **Legend**:
- Blue: Curriculum
- Orange: Anti-Curriculum
- Black: Optimal
#### Panel c) Cosine Similarity with Signal
- **X-axis**: Training time (α), linear scale 0–12.
- **Y-axis**: Cosine similarity (0–1).
- **Legend**:
- Blue (solid): Curriculum
- Orange (dashed): Anti-Curriculum
- Black (dotted): Optimal
- **Inset**: Zoomed view of α=8–12, showing convergence.
#### Panel d) Norm of Irrelevant Weights
- **X-axis**: Training time (α), linear scale 0–12.
- **Y-axis**: Norm of irrelevant weights (1–4).
- **Legend**:
- Blue (solid): Curriculum
- Orange (dashed): Anti-Curriculum
- Black (dotted): Optimal
---
### Detailed Analysis
#### Panel a) Generalization Error
- **Trend**: All protocols show decreasing error, but Optimal (black) converges fastest.
- At α=0: Curriculum (3.8×10⁻¹), Anti-Curriculum (4.0×10⁻¹), Optimal (3.5×10⁻¹).
- At α=6: Curriculum (2.3×10⁻¹), Anti-Curriculum (2.7×10⁻¹), Optimal (2.1×10⁻¹).
- At α=12: All ≈ 1.8×10⁻¹, but Optimal plateaus earliest.
#### Panel b) Difficulty Protocol
- **Curriculum**: Starts with 70% Easy (blue), transitions to 50% Easy/50% Hard by α=12.
- **Anti-Curriculum**: Starts with 70% Hard (red), transitions to 50% Easy/50% Hard by α=12.
- **Optimal**: Balanced 50% Easy/50% Hard throughout, with minor fluctuations.
#### Panel c) Cosine Similarity with Signal
- **Trend**: All protocols improve similarity, but Optimal (black) leads.
- At α=0: Curriculum (0.4), Anti-Curriculum (0.35), Optimal (0.45).
- At α=12: Curriculum (0.92), Anti-Curriculum (0.91), Optimal (0.95).
- **Inset**: At α=8–12, all protocols plateau near 0.93–0.95.
#### Panel d) Norm of Irrelevant Weights
- **Trend**: Anti-Curriculum (orange) has highest weights, Curriculum (blue) lowest.
- At α=0: Curriculum (1.0), Anti-Curriculum (1.2), Optimal (1.0).
- At α=6: Curriculum (1.5), Anti-Curriculum (3.8), Optimal (2.0).
- At α=12: Curriculum (2.2), Anti-Curriculum (4.0), Optimal (2.5).
---
### Key Observations
1. **Optimal Protocol Dominance**: Outperforms others in generalization error (a), cosine similarity (c), and irrelevant weights (d).
2. **Curriculum vs. Anti-Curriculum**:
- Curriculum reduces generalization error faster but accumulates more irrelevant weights.
- Anti-Curriculum performs worst in generalization error and irrelevant weights but matches Curriculum in cosine similarity by α=12.
3. **Difficulty Balance**: Optimal maintains a stable 50/50 difficulty split, while Curriculum/Anti-Curriculum shift toward harder tasks over time.
---
### Interpretation
The Optimal protocol demonstrates superior learning efficiency, balancing low generalization error, high signal alignment, and minimal irrelevant weights. Curriculum and Anti-Curriculum exhibit trade-offs: Curriculum prioritizes early error reduction at the cost of weight bloat, while Anti-Curriculum struggles with both error and weight management. The difficulty protocol in Panel b) suggests Optimal dynamically adjusts task difficulty to maintain equilibrium, whereas Curriculum/Anti-Curriculum skew toward extreme difficulties. The inset in Panel c) confirms that all protocols stabilize in signal alignment by late training, but Optimal achieves this with fewer irrelevant weights. These results imply that the Optimal protocol optimally balances exploration (hard tasks) and exploitation (easy tasks) for robust learning.