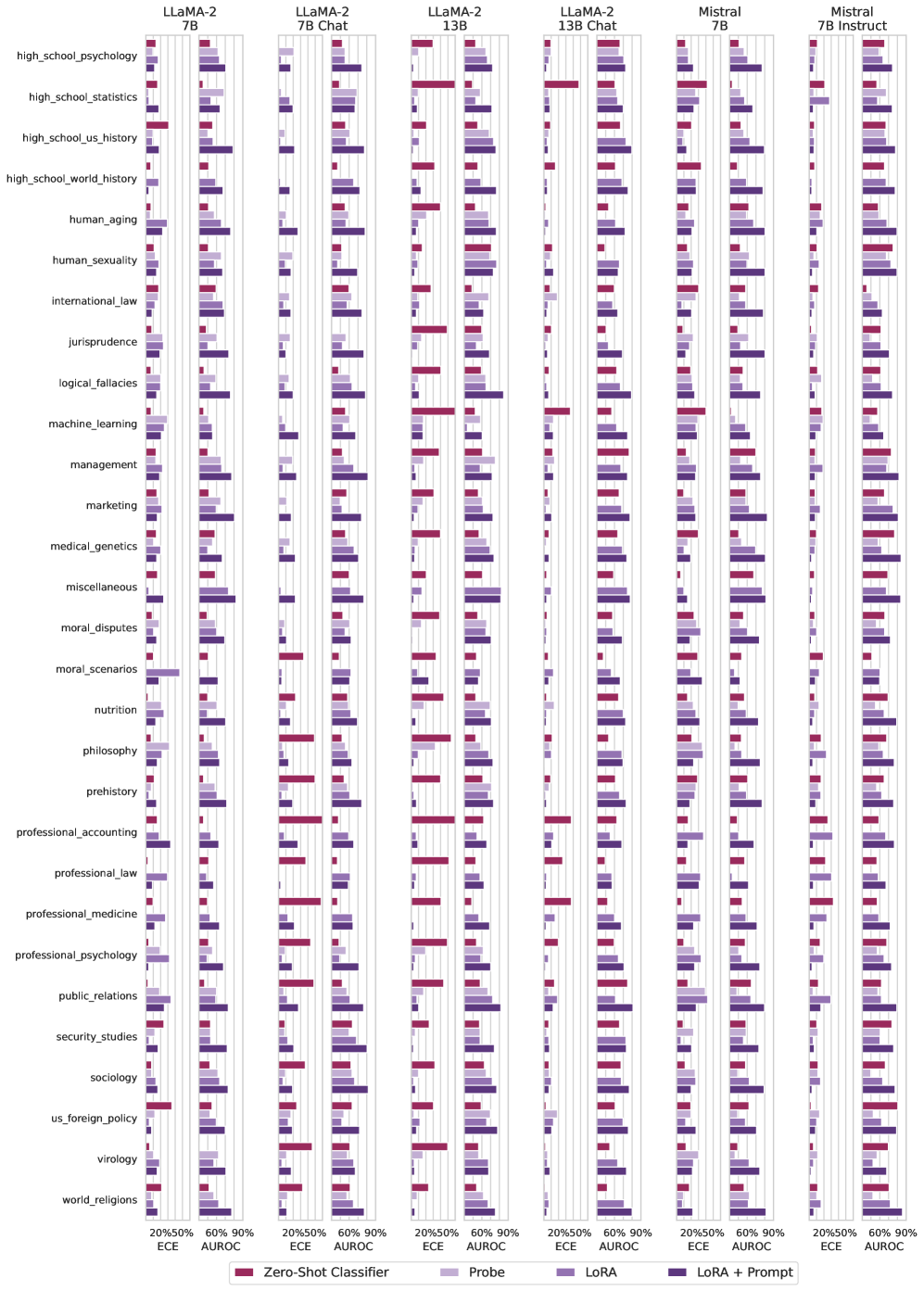
## Bar Chart: Model Performance on Various Topics
### Overview
The image is a series of bar charts comparing the performance of different language models (LLaMA-2 7B, LLaMA-2 7B Chat, LLaMA-2 13B, LLaMA-2 13B Chat, Mistral 7B, Mistral 7B Instruct) across a range of topics. Performance is measured using two metrics: ECE (Expected Calibration Error) and AUROC (Area Under the Receiver Operating Characteristic curve). Four different methods are used: Zero-Shot Classifier, Probe, LoRA, and LoRA + Prompt.
### Components/Axes
* **X-axis:** Performance metrics (ECE and AUROC) with percentage values (20%, 50%, 60%, 90%).
* **Y-axis:** List of topics, including:
* high\_school\_psychology
* high\_school\_statistics
* high\_school\_us\_history
* high\_school\_world\_history
* human\_aging
* human\_sexuality
* international\_law
* jurisprudence
* logical\_fallacies
* machine\_learning
* management
* marketing
* medical\_genetics
* miscellaneous
* moral\_disputes
* moral\_scenarios
* nutrition
* philosophy
* prehistory
* professional\_accounting
* professional\_law
* professional\_medicine
* professional\_psychology
* public\_relations
* security\_studies
* sociology
* us\_foreign\_policy
* virology
* world\_religions
* **Models (Top):**
* LLaMA-2 7B
* LLaMA-2 7B Chat
* LLaMA-2 13B
* LLaMA-2 13B Chat
* Mistral 7B
* Mistral 7B Instruct
* **Legend (Bottom):**
* Zero-Shot Classifier (Dark Red)
* Probe (Light Red)
* LoRA (Light Purple)
* LoRA + Prompt (Dark Purple)
### Detailed Analysis
The chart consists of six columns, each representing a different language model. Within each column, there are multiple horizontal bar charts, one for each topic. Each bar chart shows the performance of the model on that topic using the four different methods (Zero-Shot Classifier, Probe, LoRA, and LoRA + Prompt) for both ECE and AUROC metrics.
**General Observations:**
* **Zero-Shot Classifier (Dark Red):** Generally shows lower performance compared to other methods, especially in AUROC.
* **Probe (Light Red):** Performance varies across topics and models.
* **LoRA (Light Purple):** Generally shows better performance than Zero-Shot Classifier and Probe.
* **LoRA + Prompt (Dark Purple):** Often shows the best performance, particularly in AUROC.
**Specific Examples:**
* **high\_school\_psychology:** For LLaMA-2 7B, LoRA + Prompt (Dark Purple) has the highest AUROC, close to 90%, while Zero-Shot Classifier (Dark Red) has the lowest, around 20%.
* **machine\_learning:** LLaMA-2 13B shows a significant performance boost with LoRA + Prompt (Dark Purple) compared to Zero-Shot Classifier (Dark Red).
* **virology:** Mistral 7B Instruct shows relatively high performance across all methods.
**Model-Specific Observations:**
* **LLaMA-2 13B:** Appears to benefit more from LoRA and LoRA + Prompt compared to LLaMA-2 7B.
* **Mistral 7B Instruct:** Generally shows competitive performance across most topics.
### Key Observations
* LoRA + Prompt consistently improves performance across most models and topics.
* Zero-Shot Classifier often performs the worst, indicating the need for fine-tuning or prompting.
* The 13B models generally outperform the 7B models, especially with LoRA.
* Mistral 7B Instruct is competitive with the LLaMA-2 models.
* Performance varies significantly across topics, suggesting that some topics are more challenging for these models.
### Interpretation
The data suggests that fine-tuning language models with LoRA and providing appropriate prompts can significantly improve their performance on a variety of tasks. The Zero-Shot Classifier's poor performance highlights the importance of adapting models to specific tasks. The differences between the 7B and 13B models indicate that model size plays a role, but fine-tuning can help smaller models achieve competitive results. The consistent performance of Mistral 7B Instruct suggests it is a strong baseline model. The variability across topics indicates that some areas require more specialized training data or techniques.