TECHNICAL ASSET FINGERPRINT
35ab8fcb86fb5d95fcbceba3
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
\n
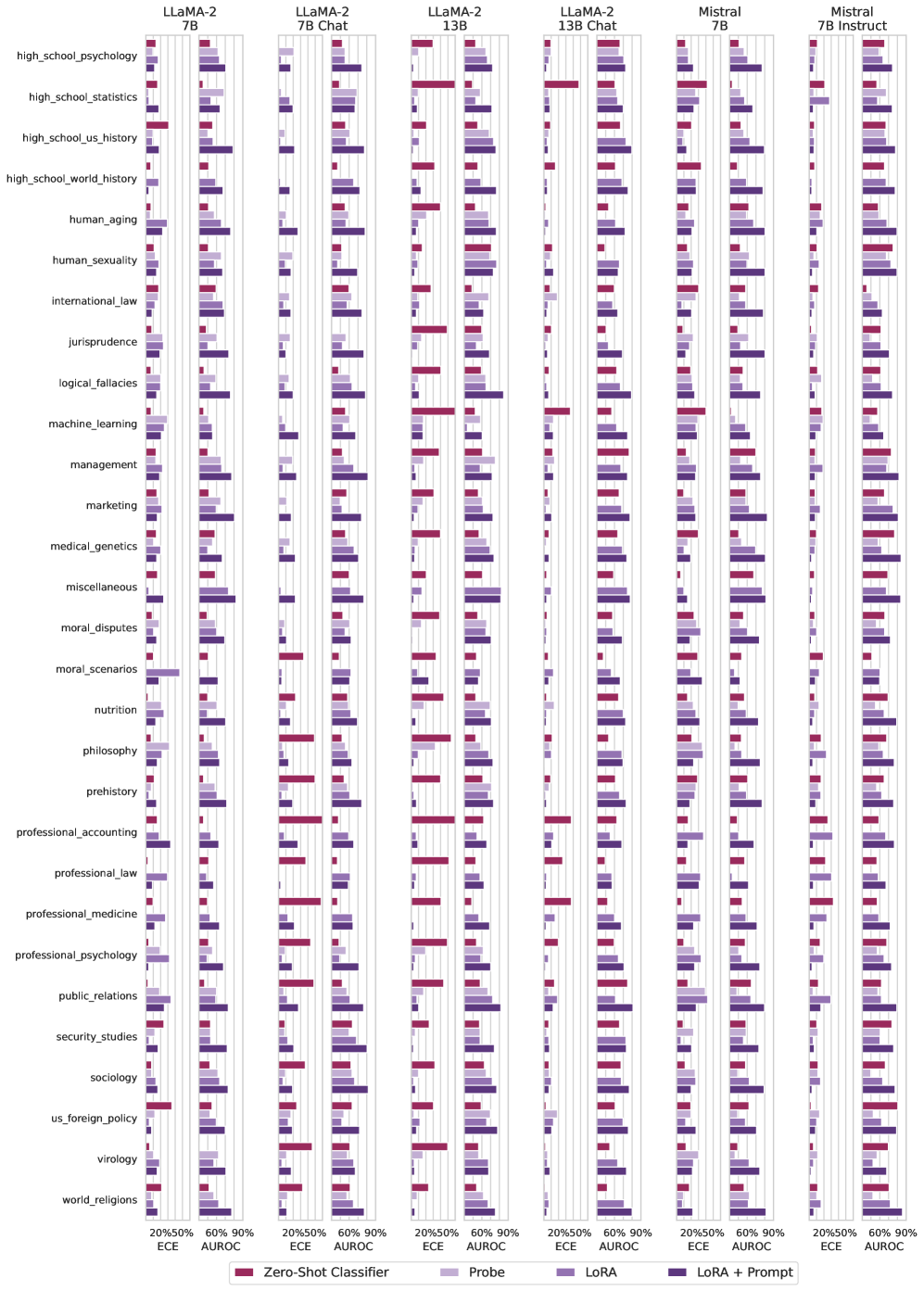
## Heatmap-Style Comparative Bar Chart: Language Model Performance Across Academic Subjects
### Overview
This image is a complex, multi-panel comparative bar chart evaluating the performance of six different Large Language Models (LLMs) across 29 academic subjects. The chart uses a grid layout where each cell contains grouped bars representing four different evaluation methods. The primary metrics are Expected Calibration Error (ECE) and Area Under the Receiver Operating Characteristic curve (AUROC), presented as percentages.
### Components/Axes
**Top Header (Model Columns):**
Six main vertical columns, each representing a distinct LLM:
1. LLaMA-2 7B
2. LLaMA-2 7B Chat
3. LLaMA-2 13B
4. LLaMA-2 13B Chat
5. Mistral 7B
6. Mistral 7B Instruct
**Sub-Columns (Metrics):**
Each model column is subdivided into two metric columns:
* **Left Sub-column:** Labeled "ECE" at the bottom. The x-axis scale shows markers at 20% and 50%.
* **Right Sub-column:** Labeled "AUROC" at the bottom. The x-axis scale shows markers at 60% and 90%.
**Y-Axis (Subjects):**
A vertical list of 29 academic subjects, from top to bottom:
`high_school_psychology`, `high_school_statistics`, `high_school_us_history`, `high_school_world_history`, `human_aging`, `human_sexuality`, `international_law`, `jurisprudence`, `logical_fallacies`, `machine_learning`, `management`, `marketing`, `medical_genetics`, `miscellaneous`, `moral_disputes`, `moral_scenarios`, `nutrition`, `philosophy`, `prehistory`, `professional_accounting`, `professional_law`, `professional_medicine`, `professional_psychology`, `public_relations`, `security_studies`, `sociology`, `us_foreign_policy`, `virology`, `world_religions`.
**Legend (Bottom Center):**
Four colored bars define the evaluation methods:
* **Red:** Zero-Shot Classifier
* **Light Purple:** Probe
* **Medium Purple:** LoRA
* **Dark Purple:** LoRA + Prompt
**Spatial Layout:**
The legend is centered at the very bottom. The model names are centered above their respective columns. Subject labels are left-aligned along the entire left edge. Each subject row contains 12 grouped bars (4 methods x 2 metrics x 6 models).
### Detailed Analysis
**General Performance Trends:**
* **AUROC vs. ECE:** Across nearly all models and subjects, the AUROC scores (right sub-column in each cell) are significantly higher than the ECE scores (left sub-column). AUROC values frequently range between 60%-90%, while ECE values are often clustered between 20%-50%.
* **Method Comparison (AUROC):** A consistent hierarchy is visible. The **LoRA + Prompt (dark purple)** method almost universally achieves the highest AUROC bars, often extending near or beyond the 90% mark. **LoRA (medium purple)** is typically second, followed by **Probe (light purple)**. The **Zero-Shot Classifier (red)** generally shows the lowest AUROC performance, with bars often ending near or below the 60% line.
* **Method Comparison (ECE):** For ECE (where lower is better), the pattern is less uniform but **Zero-Shot Classifier (red)** often has the shortest bars (best calibration), while **LoRA + Prompt (dark purple)** sometimes shows longer bars (worse calibration), suggesting a potential trade-off between discrimination (AUROC) and calibration (ECE).
**Model-Specific Observations:**
* **LLaMA-2 7B vs. 7B Chat:** The "Chat" variant generally shows slightly improved AUROC scores across many subjects compared to the base 7B model.
* **LLaMA-2 13B vs. 13B Chat:** A similar, though less pronounced, improvement from base to "Chat" variant is visible.
* **Mistral 7B vs. 7B Instruct:** The "Instruct" variant shows a clear and consistent improvement in AUROC over the base Mistral 7B model across nearly all subjects and methods.
* **Scale (7B vs. 13B):** The 13B LLaMA-2 models (both base and Chat) generally exhibit higher AUROC ceilings than their 7B counterparts, particularly for the LoRA-based methods.
**Subject-Specific Variations:**
* **High-Performing Subjects:** Subjects like `professional_accounting`, `professional_law`, and `professional_medicine` often show very high AUROC scores (>85%) for the LoRA + Prompt method across models.
* **Challenging Subjects:** Subjects such as `moral_scenarios`, `philosophy`, and `world_religions` tend to have lower overall AUROC scores and a smaller performance gap between the Zero-Shot and fine-tuned methods, indicating they may be more difficult for the models to master.
* **Notable Outlier:** In the `machine_learning` row for the `LLaMA-2 13B Chat` model, the Zero-Shot Classifier (red) AUROC bar is exceptionally long, rivaling the LoRA methods. This is an unusual deviation from the typical pattern.
### Key Observations
1. **Consistent Method Hierarchy:** The performance order (LoRA + Prompt > LoRA > Probe > Zero-Shot) for AUROC is remarkably stable across 29 subjects and 6 models.
2. **Calibration-Discrimination Trade-off:** Methods that excel at discrimination (high AUROC, like LoRA + Prompt) often show worse calibration (higher ECE).
3. **Instruction Tuning Benefit:** Both "Chat" (LLaMA-2) and "Instruct" (Mistral) variants outperform their base models, confirming the value of instruction tuning for these tasks.
4. **Domain Sensitivity:** Performance is not uniform; professional and technical subjects yield higher scores than humanities and moral reasoning subjects.
### Interpretation
This chart provides a comprehensive benchmark of LLM performance on academic multiple-choice tasks, evaluating not just accuracy (via AUROC) but also the reliability of confidence scores (via ECE).
**What the Data Suggests:**
* **Fine-Tuning is Highly Effective:** The dramatic superiority of LoRA and LoRA + Prompt methods demonstrates that lightweight fine-tuning is crucial for achieving high performance on specialized academic knowledge, far surpassing zero-shot capabilities.
* **Prompts Amplify Fine-Tuning:** The consistent edge of "LoRA + Prompt" over "LoRA" alone indicates that combining parameter-efficient fine-tuning with carefully crafted prompts yields the best results, suggesting synergy between these techniques.
* **The Cost of Performance:** The worse ECE scores for the best-performing methods imply that as models become more accurate discriminators on these tasks, their confidence scores become less calibrated. This is a critical consideration for real-world applications where reliable uncertainty estimates are needed.
* **Foundation Model Progression:** The performance jump from LLaMA-2 7B to 13B, and from base to instruction-tuned variants, illustrates the scaling and alignment laws in practice. Mistral 7B Instruct's strong performance, often matching or exceeding LLaMA-2 13B Chat, highlights rapid progress in open-weight model efficiency.
**Underlying Implications:**
The chart implicitly argues for a move beyond zero-shot evaluation in AI research. It showcases a methodology for deeply probing model capabilities across diverse domains. The persistent difficulty in subjects like `moral_scenarios` points to ongoing challenges in aligning models with nuanced human reasoning. For developers, the clear message is that to deploy LLMs in educational or professional knowledge domains, investing in domain-specific fine-tuning (like LoRA) is not just beneficial but likely necessary to reach acceptable performance levels.
DECODING INTELLIGENCE...