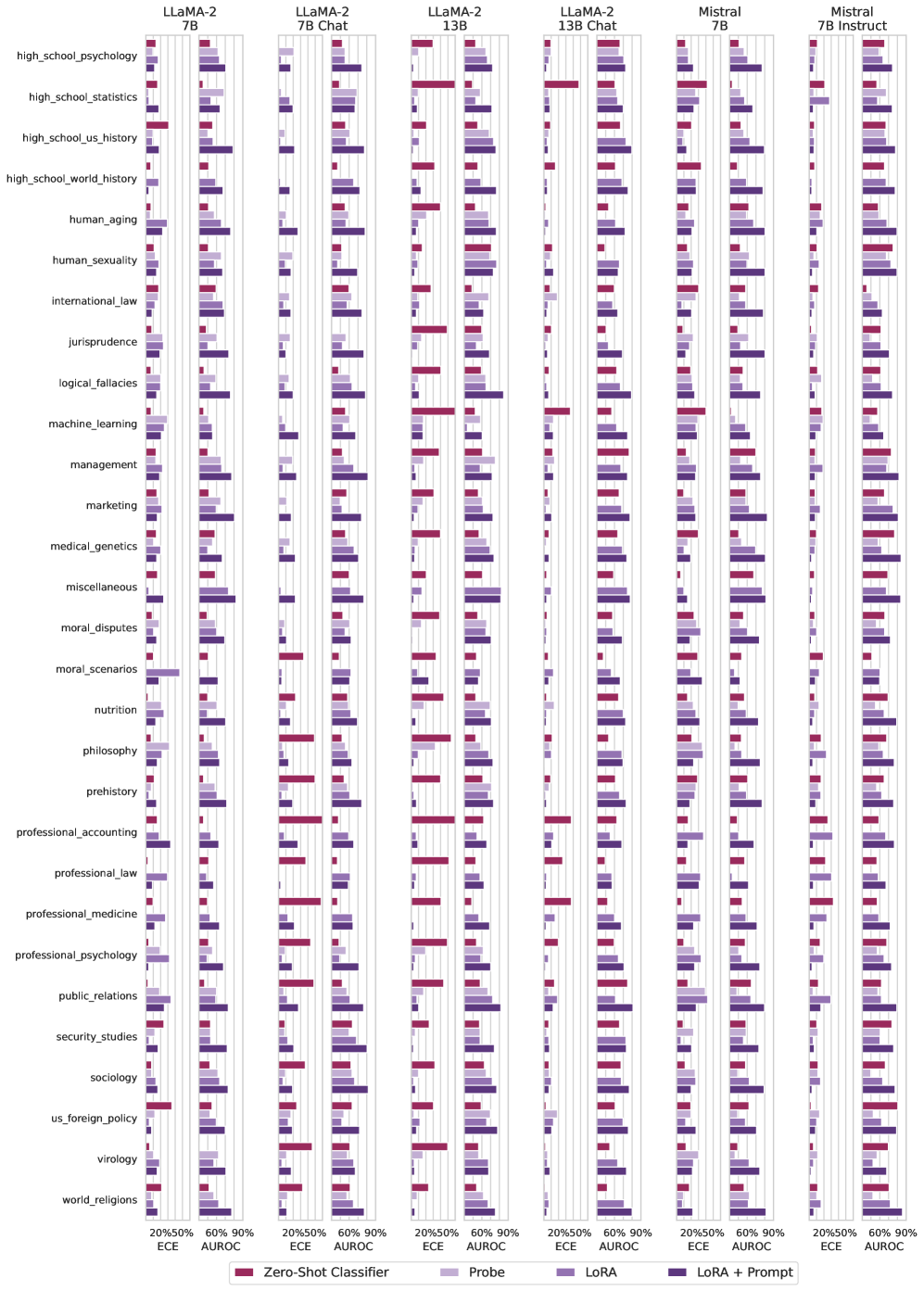
## Bar Chart: Model Performance Across Subjects by Evaluation Metrics
### Overview
The chart compares the performance of four AI models (LLaMA-2 7B, LLaMA-2 13B, Mistral 7B, Mistral 7B Instruct) across 25 subjects (e.g., high school psychology, human sexuality, international law) using two evaluation metrics: Expected Calibration Error (ECE) and Area Under the Receiver Operating Characteristic curve (AUROC). Four methods are evaluated: Zero-Shot Classifier, Probe, LoRA, and LoRA + Prompt. Bars are color-coded by method, with ECE and AUROC split along the x-axis.
### Components/Axes
- **Y-Axis**: Subjects (e.g., "high_school_psychology", "human_aging", "world_religions").
- **X-Axis**:
- **ECE**: 20%50%, 60%90% (calibration error ranges).
- **AUROC**: 20%50%, 60%90% (discrimination performance ranges).
- **Legend**:
- **Red**: Zero-Shot Classifier.
- **Light Purple**: Probe.
- **Dark Purple**: LoRA.
- **Blue**: LoRA + Prompt.
- **Model Groups**:
- LLaMA-2 7B (leftmost), LLaMA-2 13B, Mistral 7B, Mistral 7B Instruct (rightmost).
### Detailed Analysis
- **ECE Trends**:
- For most subjects, **LoRA + Prompt** (blue) shows the lowest ECE (narrowest bars), indicating better calibration.
- **Zero-Shot Classifier** (red) often has the highest ECE (widest bars), suggesting poor calibration.
- Example: In "high_school_psychology" (LLaMA-2 7B), Zero-Shot ECE ≈ 45%, Probe ≈ 35%, LoRA ≈ 30%, LoRA + Prompt ≈ 25%.
- **AUROC Trends**:
- **LoRA + Prompt** consistently achieves the highest AUROC (tallest bars), indicating superior discrimination.
- **Zero-Shot Classifier** frequently has the lowest AUROC (shortest bars).
- Example: In "human_sexuality" (Mistral 7B Instruct), Zero-Shot AUROC ≈ 55%, Probe ≈ 65%, LoRA ≈ 70%, LoRA + Prompt ≈ 75%.
### Key Observations
1. **LoRA + Prompt Dominance**: Outperforms other methods in both ECE and AUROC across nearly all subjects and models.
2. **Model Size Impact**: LLaMA-2 13B generally shows better performance than LLaMA-2 7B, particularly in AUROC.
3. **Subject Variability**:
- **High AUROC**: "prehistory" (LLaMA-2 13B, LoRA + Prompt ≈ 85%).
- **Low AUROC**: "virology" (Mistral 7B, Zero-Shot ≈ 45%).
4. **ECE Anomalies**:
- "moral_scenarios" (Mistral 7B Instruct) shows unusually high ECE for LoRA + Prompt (≈ 40%).
### Interpretation
The data demonstrates that **LoRA + Prompt** significantly enhances model performance across diverse subjects, likely by refining parameter efficiency and task-specific adaptation. The **Zero-Shot Classifier** struggles with calibration and discrimination, highlighting the need for fine-tuning. Larger models (e.g., LLaMA-2 13B) outperform smaller counterparts, but method choice (LoRA + Prompt) remains the strongest predictor of success. Outliers like "moral_scenarios" suggest domain-specific challenges requiring further investigation.