## Box Plot: Reasoning Chain Token Count
### Overview
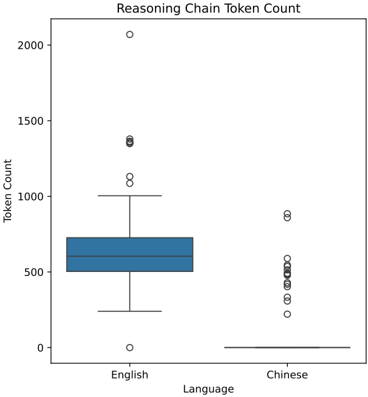
The image is a box plot comparing the distribution of "Reasoning Chain Token Count" for two languages: English and Chinese. The plot displays the median, quartiles, and outliers for each language.
### Components/Axes
* **Title:** Reasoning Chain Token Count
* **Y-axis:** Token Count, with a scale from 0 to 2000, incrementing by 500.
* **X-axis:** Language, with two categories: English and Chinese.
### Detailed Analysis
**English:**
* The box for English spans from approximately 450 to 700.
* The median (the line inside the box) is around 550.
* The lower whisker extends down to approximately 250.
* The upper whisker extends up to approximately 1000.
* There are three outliers above the upper whisker, located at approximately 1350, 1100, and 2075.
* There is one outlier below the lower whisker, located at approximately 25.
**Chinese:**
* The box for Chinese is very compressed, with the top and bottom of the box both near 0.
* The median is approximately 0.
* The lower whisker extends down to approximately 0.
* The upper whisker extends up to approximately 0.
* There are multiple outliers above the upper whisker, located at approximately 225, 375, 450, 500, 550, and 875.
### Key Observations
* The token count for English reasoning chains is generally higher and more variable than for Chinese.
* The Chinese token counts are heavily concentrated near zero, with several outliers indicating some instances of higher token counts.
* The English token counts have a more balanced distribution, with fewer extreme outliers compared to the bulk of the data.
### Interpretation
The box plot suggests that, in general, the reasoning chains in English require more tokens than those in Chinese. The concentration of Chinese token counts near zero could indicate that the reasoning chains are shorter or simpler in Chinese, or that a different tokenization method is used. The presence of outliers in both languages suggests that there are some instances where the reasoning chains require significantly more tokens than usual. The difference in token count distribution between the two languages could be due to differences in the complexity of the reasoning tasks, the linguistic properties of the languages, or the way the reasoning chains are constructed.