\n
## Box Plot: Reasoning Chain Token Count
### Overview
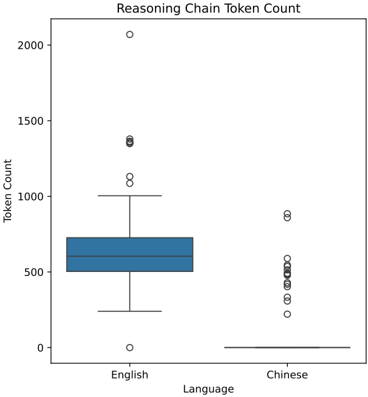
The image presents a box plot comparing the distribution of token counts in reasoning chains for English and Chinese languages. The plot displays the median, quartiles, and outliers for each language.
### Components/Axes
* **Title:** Reasoning Chain Token Count
* **X-axis:** Language (Categories: English, Chinese)
* **Y-axis:** Token Count (Scale: 0 to 2000, increments of 250)
### Detailed Analysis
The box plot shows the following:
**English:**
* The box spans approximately from 400 to 800 token counts.
* The median token count for English is around 650.
* The first quartile (Q1) is approximately 500.
* The third quartile (Q3) is approximately 750.
* There are several outliers above the upper whisker, ranging from approximately 1200 to 1400, and one outlier at approximately 2000.
* There is one outlier below the lower whisker at approximately 100.
**Chinese:**
* The box spans approximately from 200 to 400 token counts.
* The median token count for Chinese is around 300.
* The first quartile (Q1) is approximately 200.
* The third quartile (Q3) is approximately 350.
* There are several outliers above the upper whisker, ranging from approximately 500 to 1000.
* There are several outliers below the lower whisker, ranging from approximately 100 to 200.
### Key Observations
* The median token count for English reasoning chains is significantly higher than that for Chinese reasoning chains.
* The interquartile range (IQR) is smaller for Chinese than for English, indicating less variability in token counts for Chinese.
* Both languages exhibit outliers, but the range of outliers is wider for English.
* The distribution of token counts for English is more skewed to the right than that for Chinese.
### Interpretation
The data suggests that reasoning chains in English tend to be longer (require more tokens) than those in Chinese. This could be due to several factors, including differences in linguistic complexity, sentence structure, or the way reasoning is expressed in each language. The presence of outliers in both languages indicates that there are some reasoning chains that are significantly longer or shorter than the typical range. The wider range of outliers for English suggests greater variability in the length of English reasoning chains. The difference in IQR suggests that Chinese reasoning chains are more consistent in length. This could be related to the nature of the reasoning tasks or the way the data was collected. Further investigation would be needed to determine the underlying causes of these differences.