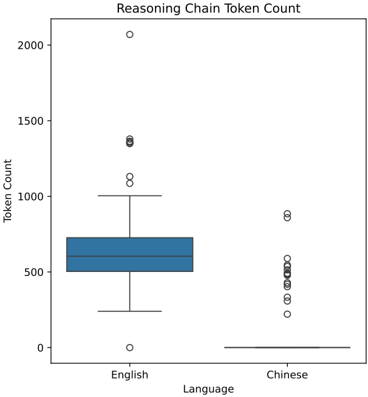
## Box Plot: Reasoning Chain Token Count
### Overview
The image is a box-and-whisker plot comparing the distribution of token counts used in reasoning chains for two languages: English and Chinese. The plot visually summarizes the central tendency, spread, and outliers for each language group.
### Components/Axes
* **Title:** "Reasoning Chain Token Count" (centered at the top).
* **Y-Axis:** Labeled "Token Count". The scale runs from 0 to 2000, with major tick marks at 0, 500, 1000, 1500, and 2000.
* **X-Axis:** Labeled "Language". It contains two categorical entries: "English" (left) and "Chinese" (right).
* **Data Series:** Two box plots.
* **English:** Represented by a blue box plot.
* **Chinese:** Represented by a gray box plot.
* **Legend/Key:** There is no separate legend box. The language labels on the x-axis serve as the key, with the color of the box plot (blue vs. gray) corresponding to the label directly below it.
### Detailed Analysis
**English (Blue Box Plot):**
* **Trend:** The distribution is broad and centered in the mid-range of the scale, with a significant number of high-value outliers.
* **Median (Central Line):** Approximately 600 tokens.
* **Interquartile Range (IQR - The Box):** The box spans from roughly 500 tokens (25th percentile) to 750 tokens (75th percentile).
* **Whiskers:** Extend from the box to the minimum and maximum non-outlier data points.
* Lower Whisker: Ends at approximately 250 tokens.
* Upper Whisker: Ends at approximately 1000 tokens.
* **Outliers (Individual Circles):** Multiple data points are plotted beyond the whiskers.
* A dense cluster exists between 1000 and 1400 tokens.
* One extreme outlier is located near the top of the chart, at approximately 2050 tokens.
* One outlier is near the bottom, at approximately 0 tokens.
**Chinese (Gray Box Plot):**
* **Trend:** The distribution is extremely compressed near the bottom of the scale, indicating very low token counts for the vast majority of cases, but with a notable set of high-value outliers.
* **Median (Central Line):** Very close to 0 tokens.
* **Interquartile Range (IQR - The Box):** The box is very narrow and sits just above the 0 line, suggesting the middle 50% of data is concentrated between approximately 0 and 50 tokens.
* **Whiskers:**
* Lower Whisker: Not visible, likely at or very near 0.
* Upper Whisker: Extends to approximately 100 tokens.
* **Outliers (Individual Circles):** A significant number of outliers are present, forming a vertical column.
* The outliers range from approximately 200 tokens up to about 900 tokens.
* The highest outlier for Chinese is near 900, which is lower than the main cluster of English outliers.
### Key Observations
1. **Stark Contrast in Central Tendency:** The median token count for English (~600) is orders of magnitude higher than for Chinese (~0). This suggests that, typically, reasoning chains expressed in English require far more tokens.
2. **Difference in Spread:** The English data has a much wider IQR and overall range (excluding outliers) than the Chinese data, indicating greater variability in the length of standard English reasoning chains.
3. **Presence of High-Value Outliers in Both:** Both languages exhibit outliers that are significantly longer than their typical chains. The English outliers reach much higher absolute values (up to ~2050) than the Chinese outliers (up to ~900).
4. **Anomalous Low English Outlier:** There is a single English data point near 0 tokens, which is an outlier on the low end for that group.
### Interpretation
This chart likely illustrates a performance or characteristic metric from a language model or a study on reasoning. The data suggests a fundamental difference in how the system (or humans) generates reasoning chains in English versus Chinese.
* **Efficiency vs. Explicitness:** The near-zero median for Chinese could indicate extreme efficiency, where reasoning is conveyed with very few tokens. Alternatively, it might suggest the model's reasoning process in Chinese is less verbose or explicit by default. The higher English median implies a more elaborate, step-by-step articulation of thought.
* **Outlier Analysis:** The high outliers in both languages represent complex problems requiring extensive reasoning. The fact that English outliers are higher may indicate that the most complex reasoning tasks, when forced into an English expression, become exceptionally verbose. The cluster of Chinese outliers between 200-900 tokens shows that complex reasoning in Chinese also requires more tokens, but not to the same extreme as in English.
* **Potential Implications:** This has practical implications for token budgeting and cost in AI systems. It also raises questions about the underlying cognitive or architectural biases of the model—whether it "thinks" more concisely in one language or is simply trained to respond more concisely. The single low English outlier is curious and could be an error or a case of minimal, non-standard reasoning.
**Language Note:** All text in the image is in English.