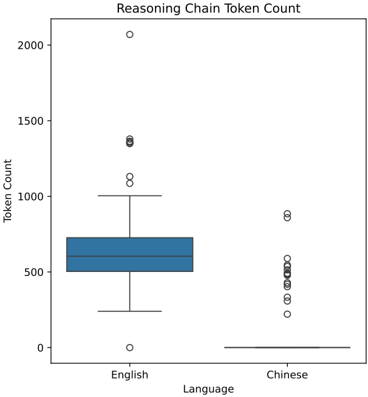
## Box Plot: Reasoning Chain Token Count
### Overview
The image displays a comparative box plot analyzing token counts for reasoning chains in two languages: English and Chinese. The y-axis represents token counts (0–2000), while the x-axis categorizes data by language. Two box plots are positioned side-by-side, with English on the left and Chinese on the right. Outliers are marked as individual points outside the whiskers.
### Components/Axes
- **X-Axis (Language)**: Labeled "Language," with categories "English" (left) and "Chinese" (right).
- **Y-Axis (Token Count)**: Labeled "Token Count," scaled from 0 to 2000 in increments of 500.
- **Legend**: Located on the right side of the plot, associating colors with languages:
- **Blue**: English
- **Black**: Chinese
- **Box Plot Elements**:
- **Median**: Horizontal line within each box.
- **Interquartile Range (IQR)**: Box boundaries (25th–75th percentiles).
- **Whiskers**: Extend to 1.5×IQR from the quartiles.
- **Outliers**: Points beyond whiskers (e.g., English: 1000, 2000; Chinese: 500, 900).
### Detailed Analysis
- **English**:
- **Median**: ~600 tokens.
- **IQR**: ~400–800 tokens.
- **Outliers**: 1000 and 2000 tokens.
- **Whiskers**: ~300–1000 tokens.
- **Chinese**:
- **Median**: ~400 tokens.
- **IQR**: ~300–500 tokens.
- **Outliers**: 500 and 900 tokens.
- **Whiskers**: ~200–900 tokens.
### Key Observations
1. **Higher Median for English**: English reasoning chains consistently use more tokens (~600 vs. ~400 for Chinese).
2. **Wider Distribution in English**: English data spans a broader range (~300–2000) compared to Chinese (~200–900).
3. **Outlier Disparity**: English has a single extreme outlier at 2000 tokens, while Chinese outliers cluster closer to the median.
4. **Consistency in Chinese**: Chinese data shows tighter clustering, with fewer extreme values.
### Interpretation
The data suggests that English reasoning chains require significantly more tokens on average, potentially due to:
- **Language Complexity**: English may require more granular tokenization or longer reasoning steps.
- **Model Behavior**: The model might generate more verbose outputs for English, possibly reflecting training data biases or linguistic structure differences.
- **Outlier Causes**: The 2000-token outlier in English warrants investigation—could represent edge cases (e.g., complex queries) or data anomalies.
The tighter distribution in Chinese indicates more predictable token usage, which might simplify computational efficiency for Chinese-specific applications. However, the presence of outliers in both languages highlights variability that could impact system performance or resource allocation.