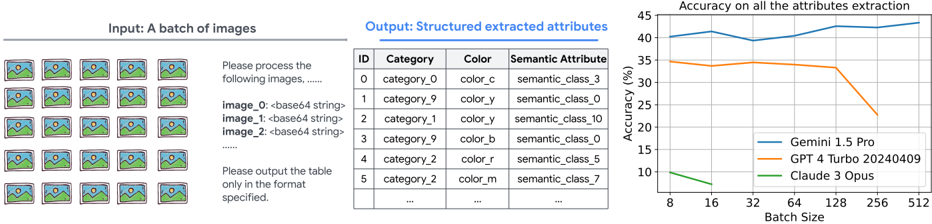
## Image Analysis: Model Attribute Extraction Accuracy
### Overview
The image presents a comparison of three models (Gemini 1.5 Pro, GPT 4 Turbo 20240409, and Claude 3 Opus) in terms of their accuracy on attribute extraction from images. It shows the input as a batch of images, the desired structured output format, and a line graph comparing the accuracy of the models across different batch sizes.
### Components/Axes
* **Input:** A batch of images, represented by a grid of 20 small images. The text "Please process the following images,..." is present, along with examples of image names and their base64 string representations (e.g., "image_0: <base64 string>").
* **Output:** A table illustrating the desired structured output format. The table has the following columns:
* ID
* Category
* Color
* Semantic Attribute
Example rows are provided, such as:
* 0: category_0, color_c, semantic_class_3
* 1: category_9, color_y, semantic_class_0
* 2: category_1, color_y, semantic_class_10
* 3: category_9, color_b, semantic_class_0
* 4: category_2, color_r, semantic_class_5
* 5: category_2, color_m, semantic_class_7
* **Accuracy Chart:**
* **Title:** "Accuracy on all the attributes extraction"
* **X-axis:** "Batch Size" with values 8, 16, 32, 64, 128, 256, 512.
* **Y-axis:** "Accuracy (%)" with a scale from 10 to 45, incrementing by 5.
* **Legend:** Located in the bottom-right corner of the chart.
* Blue line: Gemini 1.5 Pro
* Orange line: GPT 4 Turbo 20240409
* Green line: Claude 3 Opus
### Detailed Analysis
**Accuracy Chart Data:**
* **Gemini 1.5 Pro (Blue):**
* Batch Size 8: Accuracy ~40%
* Batch Size 16: Accuracy ~41%
* Batch Size 32: Accuracy ~42%
* Batch Size 64: Accuracy ~41%
* Batch Size 128: Accuracy ~41%
* Batch Size 256: Accuracy ~41%
* Batch Size 512: Accuracy ~40%
* Trend: Relatively stable accuracy across all batch sizes, hovering around 41%.
* **GPT 4 Turbo 20240409 (Orange):**
* Batch Size 8: Accuracy ~34%
* Batch Size 16: Accuracy ~34%
* Batch Size 32: Accuracy ~34%
* Batch Size 64: Accuracy ~34%
* Batch Size 128: Accuracy ~34%
* Batch Size 256: Accuracy ~31%
* Batch Size 512: Accuracy ~24%
* Trend: Stable accuracy until batch size 128, then a significant drop in accuracy at batch sizes 256 and 512.
* **Claude 3 Opus (Green):**
* Batch Size 8: Accuracy ~11%
* Batch Size 16: Accuracy ~8%
* Trend: Low accuracy, decreasing slightly from batch size 8 to 16.
### Key Observations
* Gemini 1.5 Pro consistently outperforms the other two models in terms of accuracy across all batch sizes.
* GPT 4 Turbo 20240409 maintains a relatively stable accuracy until a batch size of 128, after which its performance degrades significantly.
* Claude 3 Opus has the lowest accuracy among the three models.
* The performance of Gemini 1.5 Pro is largely unaffected by changes in batch size, while GPT 4 Turbo 20240409 is sensitive to larger batch sizes.
### Interpretation
The data suggests that Gemini 1.5 Pro is the most robust model for attribute extraction, maintaining high accuracy regardless of batch size. GPT 4 Turbo 20240409 is competitive at smaller batch sizes but struggles with larger batches, indicating a potential limitation in its ability to process large amounts of data efficiently. Claude 3 Opus appears to be the least effective of the three models for this particular task. The relationship between batch size and accuracy highlights the importance of considering computational resources and model architecture when selecting a model for attribute extraction. The drop in accuracy for GPT 4 Turbo at larger batch sizes could be due to memory limitations or other constraints that affect its ability to process the data effectively.