\n
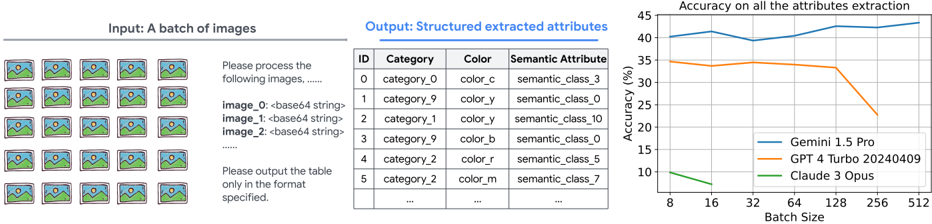
## Chart: Accuracy on All Attributes Extraction vs. Batch Size
### Overview
The image presents a line chart comparing the accuracy of three different models – Gemini 1.5 Pro, GPT 4 Turbo 20240409, and Claude 3 Opus – on attribute extraction, as a function of batch size. To the left of the chart are example images and a sample output table demonstrating the expected structured attribute extraction format.
### Components/Axes
* **X-axis:** Batch Size, ranging from 8 to 512. The scale is logarithmic, with markers at 8, 16, 32, 64, 128, 256, and 512.
* **Y-axis:** Accuracy (%), ranging from 0 to 45.
* **Lines:** Three distinct lines representing the accuracy of each model:
* Gemini 1.5 Pro (Blue)
* GPT 4 Turbo 20240409 (Orange)
* Claude 3 Opus (Green)
* **Legend:** Located in the bottom-right corner, clearly labeling each line with its corresponding model name and color.
* **Input Example:** A grid of 9 images is shown on the top-left, representing a batch of images to be processed.
* **Output Example:** A table is shown in the center-left, demonstrating the expected structured output format. The table has columns labeled "ID", "Category", "Color", and "Semantic Attribute".
### Detailed Analysis
Let's analyze the trends and data points for each model:
* **Gemini 1.5 Pro (Blue):** The line starts at approximately 41% accuracy at a batch size of 8. It initially increases to a peak of around 43% at a batch size of 32, then plateaus and slightly decreases to approximately 42% at a batch size of 512.
* **GPT 4 Turbo 20240409 (Orange):** The line begins at approximately 36% accuracy at a batch size of 8. It increases to a peak of around 38% at a batch size of 32, then declines sharply to approximately 27% at a batch size of 512.
* **Claude 3 Opus (Green):** The line starts at approximately 10% accuracy at a batch size of 8. It increases rapidly to approximately 32% at a batch size of 64, then continues to increase more slowly, reaching approximately 35% at a batch size of 512.
**Table Data (Sample):**
| ID | Category | Color | Semantic Attribute |
| --------- | ---------- | ----- | ------------------ |
| category_0 | color_c | semantic_class_3 |
| category_9 | color_y | semantic_class_0 |
| category_1 | color_y | semantic_class_10|
| category_9 | color_b | semantic_class_b |
| category_2 | color_r | semantic_class_5 |
| category_2 | color_m | semantic_class_7 |
| ... | ... | ... | ... |
The table shows the expected output format, with each row representing an extracted attribute from an image. The columns indicate the ID of the object, its category, color, and semantic attribute.
### Key Observations
* Gemini 1.5 Pro consistently exhibits the highest accuracy across all batch sizes.
* GPT 4 Turbo 20240409 shows a significant decline in accuracy as the batch size increases.
* Claude 3 Opus demonstrates the most substantial improvement in accuracy with increasing batch size, starting from a low base but eventually approaching the performance of GPT 4 Turbo.
* The performance of GPT 4 Turbo degrades significantly at larger batch sizes, suggesting potential limitations in handling larger inputs.
### Interpretation
The chart demonstrates the performance of three large language models on an attribute extraction task, varying the batch size of input images. Gemini 1.5 Pro appears to be the most robust model, maintaining relatively high accuracy regardless of batch size. GPT 4 Turbo 20240409, while initially competitive, suffers a substantial performance drop with larger batches, indicating potential scalability issues. Claude 3 Opus shows a strong positive correlation between batch size and accuracy, suggesting it benefits from processing larger datasets, but starts with a lower baseline.
The sample output table illustrates the structured format of the extracted attributes, which is crucial for downstream applications. The fact that the models are extracting "Semantic Attributes" suggests they are not merely identifying objects but also understanding their meaning and relationships within the images.
The observed trends suggest that model architecture and training data play a significant role in determining scalability and robustness. Gemini 1.5 Pro's consistent performance may be attributed to its architecture or training methodology, while GPT 4 Turbo's decline could be due to limitations in its attention mechanism or memory capacity. Claude 3 Opus's improvement with batch size might indicate that it benefits from more contextual information available in larger batches.