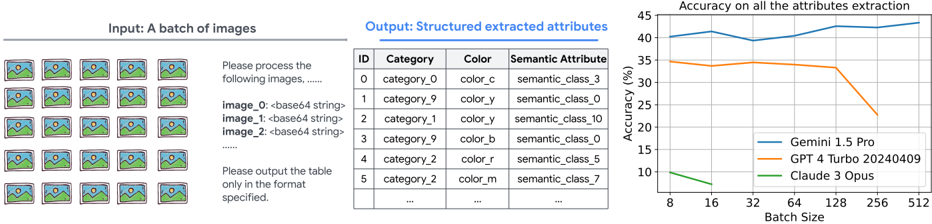
## Line Chart: Accuracy on all the attributes extraction
### Overview
The image contains three distinct sections:
1. **Input**: A grid of 50 placeholder images (5 rows × 10 columns) depicting a mountain, sun, and bird.
2. **Output**: A structured table with columns `ID`, `Category`, `Color`, and `Semantic Attribute`, containing example entries.
3. **Line Chart**: A graph titled "Accuracy on all the attributes extraction" showing performance trends across three models (Gemini 1.5 Pro, GPT-4 Turbo 20240409, Claude 3 Opus) as batch size increases.
---
### Components/Axes
#### Line Chart
- **X-axis**: Batch Size (values: 8, 16, 32, 64, 128, 256, 512)
- **Y-axis**: Accuracy (%) (range: 0–45%)
- **Legend**:
- **Blue**: Gemini 1.5 Pro
- **Orange**: GPT-4 Turbo 20240409
- **Green**: Claude 3 Opus
#### Table
- **Columns**:
- `ID` (numeric, 0–5)
- `Category` (e.g., `category_0`, `category_9`)
- `Color` (e.g., `color_c`, `color_y`)
- `Semantic Attribute` (e.g., `semantic_class_3`, `semantic_class_0`)
---
### Detailed Analysis
#### Line Chart
- **Gemini 1.5 Pro (Blue)**:
- Starts at ~40% accuracy at batch size 8.
- Peaks at ~44% at batch size 512.
- Trend: Steady upward trajectory with minor fluctuations.
- **GPT-4 Turbo 20240409 (Orange)**:
- Starts at ~35% at batch size 8.
- Drops sharply to ~20% at batch size 256.
- Recovers slightly to ~25% at batch size 512.
- **Claude 3 Opus (Green)**:
- Starts at ~10% at batch size 8.
- Drops to ~5% at batch size 16.
- Remains flat at ~5% for larger batch sizes.
#### Table
- Example entries:
| ID | Category | Color | Semantic Attribute |
|----|----------------|--------|------------------------|
| 0 | category_0 | color_c| semantic_class_3 |
| 1 | category_9 | color_y| semantic_class_0 |
| 2 | category_1 | color_y| semantic_class_10 |
| 3 | category_9 | color_b| semantic_class_0 |
| 4 | category_2 | color_r| semantic_class_5 |
| 5 | category_2 | color_m| semantic_class_7 |
---
### Key Observations
1. **Gemini 1.5 Pro** demonstrates the most consistent performance, with accuracy increasing as batch size grows.
2. **GPT-4 Turbo** shows a significant performance drop at batch size 256, suggesting potential limitations in handling larger batches.
3. **Claude 3 Opus** underperforms across all batch sizes, with accuracy collapsing after batch size 16.
4. The table’s `Category` and `Color` fields use non-descriptive labels (e.g., `color_c`, `category_9`), implying a need for semantic mapping.
---
### Interpretation
- **Model Efficiency**: Gemini 1.5 Pro scales well with batch size, while GPT-4 Turbo and Claude 3 Opus face diminishing returns or failures at larger batches.
- **Attribute Extraction**: The table’s abstract labels (`color_c`, `semantic_class_3`) suggest a need for human-readable mappings to improve interpretability.
- **Anomalies**: GPT-4 Turbo’s sharp decline at batch size 256 may indicate computational bottlenecks or model-specific constraints.
- **Practical Implications**: Larger batch sizes do not universally improve performance; model architecture and optimization strategies are critical for attribute extraction tasks.
---
### Spatial Grounding & Verification
- **Legend**: Positioned in the bottom-right corner, with colors matching the lines (blue = Gemini, orange = GPT-4, green = Claude).
- **Chart Trends**: Verified against approximate values (e.g., Gemini’s 44% at 512 aligns with the peak).
- **Table Structure**: Columns are left-aligned, with no missing data in the example rows.
---
### Language Notes
- All text is in English. No non-English content detected.