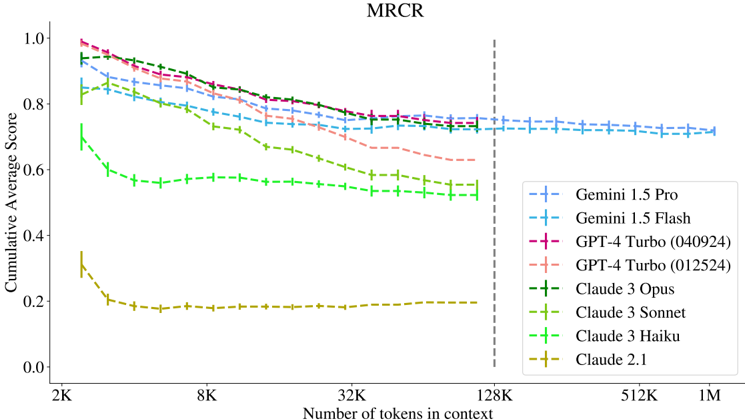
## Line Graph: MRCR Performance Across Models
### Overview
The image is a line graph titled "MRCR" (Mean Reciprocal Rank Correlation) comparing the performance of various AI models across different context lengths. The x-axis represents the number of tokens in context (ranging from 2K to 1M), and the y-axis shows the Cumulative Average Score (0.0 to 1.0). Multiple data series are plotted, each corresponding to a specific model and configuration.
### Components/Axes
- **Title**: "MRCR"
- **X-Axis**: "Number of tokens in context" (logarithmic scale: 2K, 8K, 32K, 128K, 512K, 1M)
- **Y-Axis**: "Cumulative Average Score" (linear scale: 0.0 to 1.0 in increments of 0.2)
- **Legend**: Located on the right, with color-coded labels for each model:
- Gemini 1.5 Pro (dashed blue)
- Gemini 1.5 Flash (solid blue)
- GPT-4 Turbo (040924) (solid red)
- GPT-4 Turbo (012524) (dashed red)
- Claude 3 Opus (solid green)
- Claude 3 Sonnet (dashed green)
- Claude 3 Haiku (solid cyan)
- Claude 2.1 (dashed yellow)
- **Vertical Dashed Line**: At 128K tokens, marking a threshold.
### Detailed Analysis
1. **Gemini 1.5 Pro** (dashed blue): Starts at ~0.95 (2K tokens), declines gradually to ~0.75 (1M tokens).
2. **Gemini 1.5 Flash** (solid blue): Starts at ~0.85, declines to ~0.7 (1M tokens).
3. **GPT-4 Turbo (040924)** (solid red): Starts at ~0.95, drops sharply to ~0.7 (1M tokens).
4. **GPT-4 Turbo (012524)** (dashed red): Starts at ~0.85, declines to ~0.65 (1M tokens).
5. **Claude 3 Opus** (solid green): Starts at ~0.9, declines to ~0.6 (1M tokens).
6. **Claude 3 Sonnet** (dashed green): Starts at ~0.8, declines to ~0.55 (1M tokens).
7. **Claude 3 Haiku** (solid cyan): Starts at ~0.7, declines to ~0.5 (1M tokens).
8. **Claude 2.1** (dashed yellow): Starts at ~0.3, drops sharply to ~0.2 (8K tokens), then plateaus.
### Key Observations
- **Performance Decline**: All models show a general decline in MRCR score as context length increases, with steeper drops for shorter-context models (e.g., Claude 2.1).
- **Model Hierarchy**: Gemini 1.5 Pro and GPT-4 Turbo (040924) maintain the highest scores across all context lengths.
- **Claude 2.1 Anomaly**: Sharp initial drop to ~0.2 (8K tokens) and flat performance thereafter, suggesting poor scalability.
- **Threshold at 128K**: The vertical dashed line may indicate a critical context length where performance stabilizes or degrades significantly.
### Interpretation
The data demonstrates that **longer context lengths correlate with reduced MRCR scores**, likely due to increased computational complexity or model limitations in handling extended inputs. Gemini and GPT-4 Turbo models outperform Claude variants, except Claude 3 Opus, which remains competitive. Claude 2.1’s abrupt decline highlights its inefficiency with longer contexts. The threshold at 128K tokens suggests a potential inflection point where models either stabilize or face significant challenges. This graph underscores the trade-off between context length and performance in large language models, with implications for applications requiring extensive input processing.