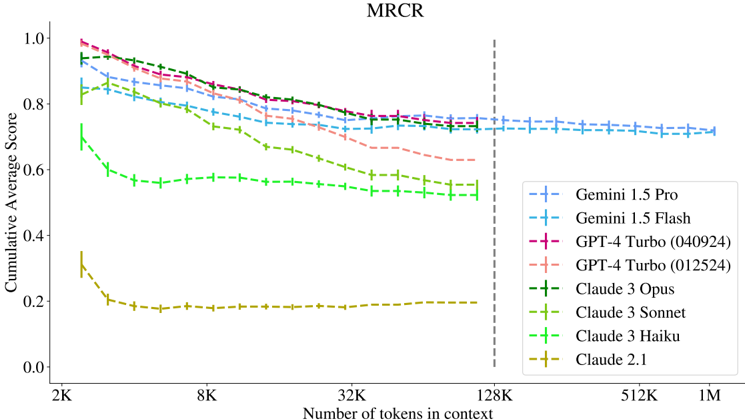
## Chart: MRCR Cumulative Average Score vs. Number of Tokens in Context
### Overview
The image is a line chart comparing the cumulative average score of several language models (Gemini 1.5 Pro, Gemini 1.5 Flash, GPT-4 Turbo (040924), GPT-4 Turbo (012524), Claude 3 Opus, Claude 3 Sonnet, Claude 3 Haiku, and Claude 2.1) against the number of tokens in context. The x-axis represents the number of tokens in context, ranging from 2K to 1M. The y-axis represents the cumulative average score, ranging from 0.0 to 1.0. A vertical dashed line is present at 128K tokens.
### Components/Axes
* **Title:** MRCR
* **X-axis Title:** Number of tokens in context
* **X-axis Scale:** 2K, 8K, 32K, 128K, 512K, 1M (logarithmic scale)
* **Y-axis Title:** Cumulative Average Score
* **Y-axis Scale:** 0.0, 0.2, 0.4, 0.6, 0.8, 1.0
* **Legend (bottom-right):**
* Blue: Gemini 1.5 Pro
* Light Blue: Gemini 1.5 Flash
* Dark Pink: GPT-4 Turbo (040924)
* Light Pink: GPT-4 Turbo (012524)
* Dark Green: Claude 3 Opus
* Green: Claude 3 Sonnet
* Light Green: Claude 3 Haiku
* Olive/Yellow: Claude 2.1
* **Vertical Dashed Line:** Located at 128K tokens in context.
### Detailed Analysis
* **Gemini 1.5 Pro (Blue):** Starts at approximately 0.85 and decreases gradually to approximately 0.72 as the number of tokens increases.
* **Gemini 1.5 Flash (Light Blue):** Starts at approximately 0.95 and decreases gradually to approximately 0.72 as the number of tokens increases.
* **GPT-4 Turbo (040924) (Dark Pink):** Starts at approximately 0.97 and decreases gradually to approximately 0.75 as the number of tokens increases.
* **GPT-4 Turbo (012524) (Light Pink):** Starts at approximately 0.92 and decreases gradually to approximately 0.68 as the number of tokens increases.
* **Claude 3 Opus (Dark Green):** Starts at approximately 0.88 and decreases gradually to approximately 0.73 as the number of tokens increases.
* **Claude 3 Sonnet (Green):** Starts at approximately 0.75 and decreases gradually to approximately 0.55 as the number of tokens increases.
* **Claude 3 Haiku (Light Green):** Starts at approximately 0.70 and decreases gradually to approximately 0.57 as the number of tokens increases.
* **Claude 2.1 (Olive/Yellow):** Starts at approximately 0.35 and decreases rapidly to approximately 0.18, then remains relatively constant.
### Key Observations
* All models except Claude 2.1 show a decrease in cumulative average score as the number of tokens in context increases.
* GPT-4 Turbo (040924) and Gemini 1.5 Flash have the highest initial scores.
* Claude 2.1 has the lowest scores across all token counts.
* The performance of all models appears to stabilize beyond 128K tokens.
### Interpretation
The chart illustrates the performance of different language models as the context length increases. The general trend suggests that the cumulative average score decreases with longer context lengths, indicating a potential challenge in maintaining performance with more extensive input. Claude 2.1's significantly lower performance suggests it may not be as effective in this particular task compared to the other models. The vertical line at 128K tokens might indicate a significant threshold or a point where the models' performance stabilizes. The data suggests that while some models start with higher scores, the performance gap narrows as the context length increases, implying that the ability to handle long contexts effectively is a crucial factor in overall performance.