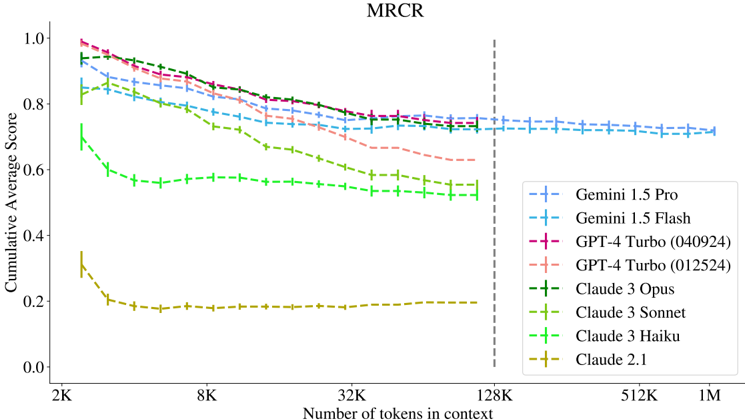
## Line Chart: MRCR Performance
### Overview
This line chart depicts the Cumulative Average Score of several Large Language Models (LLMs) on a task labeled "MRCR" as a function of the number of tokens in context. The x-axis represents the number of tokens, ranging from 2K to 1M, while the y-axis represents the Cumulative Average Score, ranging from 0.0 to 1.0. The chart compares the performance of Gemini 1.5 Pro, Gemini 1.5 Flash, GPT-4 Turbo (two versions), Claude 3 Opus, Claude 3 Sonnet, Claude 3 Haiku, and Claude 2.1. A vertical dashed line is present at 128K tokens.
### Components/Axes
* **Title:** MRCR (top-center)
* **X-axis Label:** Number of tokens in context (bottom-center)
* **X-axis Markers:** 2K, 8K, 32K, 128K, 512K, 1M
* **Y-axis Label:** Cumulative Average Score (left-center)
* **Y-axis Scale:** 0.0 to 1.0
* **Legend:** Located in the top-right corner.
* **Legend Entries:**
* Gemini 1.5 Pro (Blue, dashed line)
* Gemini 1.5 Flash (Cyan, dashed line)
* GPT-4 Turbo (040924) (Magenta, dashed line)
* GPT-4 Turbo (012524) (Red, dashed line)
* Claude 3 Opus (Green, dashed line)
* Claude 3 Sonnet (Olive, dashed line)
* Claude 3 Haiku (Light Green, dashed line)
* Claude 2.1 (Orange, dashed line)
### Detailed Analysis
Here's a breakdown of each line's trend and approximate data points, verifying color consistency with the legend:
* **Gemini 1.5 Pro (Blue, dashed):** Starts at approximately 0.92 at 2K tokens, gradually decreases to around 0.74 at 128K tokens, and remains relatively stable around 0.72-0.75 up to 1M tokens.
* **Gemini 1.5 Flash (Cyan, dashed):** Begins at approximately 0.85 at 2K tokens, declines to around 0.70 at 128K tokens, and stabilizes around 0.68-0.72 up to 1M tokens.
* **GPT-4 Turbo (040924) (Magenta, dashed):** Starts at approximately 0.90 at 2K tokens, decreases to around 0.76 at 128K tokens, and remains relatively stable around 0.73-0.76 up to 1M tokens.
* **GPT-4 Turbo (012524) (Red, dashed):** Starts at approximately 0.88 at 2K tokens, declines to around 0.72 at 128K tokens, and stabilizes around 0.68-0.72 up to 1M tokens.
* **Claude 3 Opus (Green, dashed):** Starts at approximately 0.72 at 2K tokens, decreases to around 0.52 at 128K tokens, and stabilizes around 0.50-0.55 up to 1M tokens.
* **Claude 3 Sonnet (Olive, dashed):** Begins at approximately 0.65 at 2K tokens, declines to around 0.45 at 128K tokens, and stabilizes around 0.40-0.45 up to 1M tokens.
* **Claude 3 Haiku (Light Green, dashed):** Starts at approximately 0.60 at 2K tokens, decreases to around 0.40 at 128K tokens, and stabilizes around 0.35-0.40 up to 1M tokens.
* **Claude 2.1 (Orange, dashed):** Starts at approximately 0.22 at 2K tokens, decreases to around 0.18 at 128K tokens, and stabilizes around 0.16-0.20 up to 1M tokens.
### Key Observations
* All models exhibit a decreasing trend in Cumulative Average Score as the number of tokens in context increases, particularly up to 128K tokens.
* Gemini 1.5 Pro and GPT-4 Turbo models consistently achieve the highest scores across all token lengths.
* Claude 2.1 consistently performs the worst, with significantly lower scores than the other models.
* The rate of score decrease appears to slow down after 128K tokens for most models.
* The two versions of GPT-4 Turbo show slight differences in performance, with the 040924 version generally performing slightly better.
### Interpretation
The chart demonstrates the performance of various LLMs on the MRCR task as a function of context window size. The initial decline in performance with increasing tokens suggests that the models may struggle to effectively utilize information from very large contexts, potentially due to attention limitations or computational constraints. The stabilization of scores after 128K tokens could indicate that the models reach a point where adding more tokens provides diminishing returns or that they have developed mechanisms to handle larger contexts more efficiently.
The consistent superior performance of Gemini 1.5 Pro and GPT-4 Turbo suggests that these models are better equipped to handle long-context tasks compared to the Claude models and Claude 2.1. The significant gap in performance between Claude 2.1 and the other models highlights the importance of model architecture and training data in achieving strong long-context capabilities. The vertical dashed line at 128K tokens may represent a significant architectural change or training cutoff point for some of the models, influencing the observed performance trends. Further investigation into the MRCR task itself would be needed to understand the specific challenges it presents and why certain models excel while others struggle.