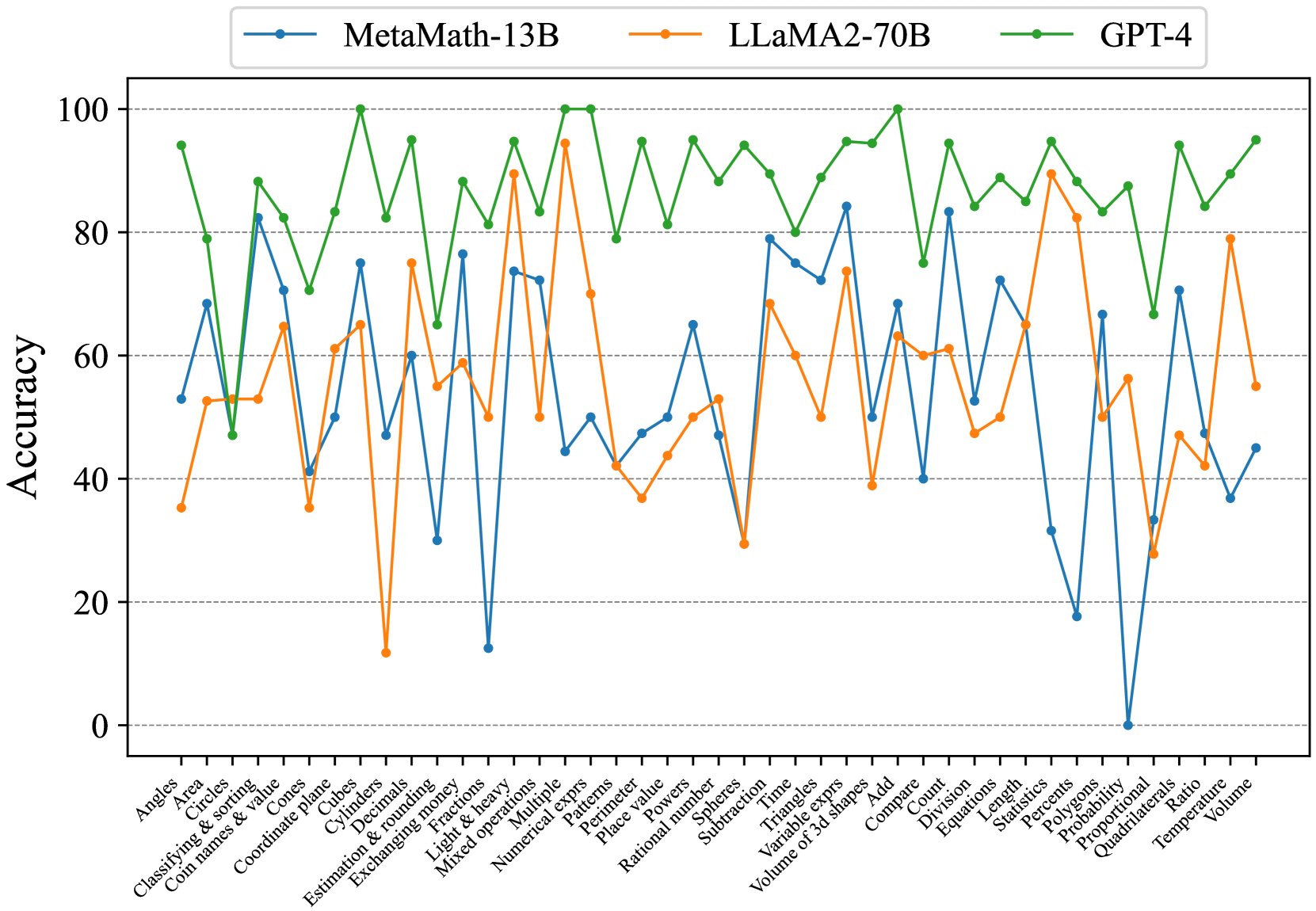
## Line Chart: Model Accuracy Across Math Topics
### Overview
The chart compares the accuracy of three AI models (MetaMath-13B, LLaMA2-70B, GPT-4) across 30 math-related topics. Accuracy is measured on a 0-100% scale, with notable fluctuations observed across models and topics.
### Components/Axes
- **X-axis**: Math topics (Angles, Area, Circles, ..., Volume)
- **Y-axis**: Accuracy (0-100%, increments of 20)
- **Legend**: Top-left corner, mapping colors to models:
- Blue: MetaMath-13B
- Orange: LLaMA2-70B
- Green: GPT-4
### Detailed Analysis
1. **MetaMath-13B (Blue Line)**
- **Trend**: Highly variable performance, with sharp peaks and troughs.
- **Key Data Points**:
- Peaks at ~85% in "Circles & sorting" and "Estimation & rounding".
- Drops to **0%** in "Probability" (notable outlier).
- Ends at ~45% in "Volume".
2. **LLaMA2-70B (Orange Line)**
- **Trend**: Moderate consistency, with fewer extreme fluctuations.
- **Key Data Points**:
- Peaks at ~90% in "Numerical exponents" and "Length".
- Lowest point at ~30% in "Decimals".
- Ends at ~55% in "Volume".
3. **GPT-4 (Green Line)**
- **Trend**: Most stable and highest-performing overall.
- **Key Data Points**:
- Peaks at **100%** in "Circles & sorting" and "Estimation & rounding".
- Rarely drops below 80% (e.g., "Decimals" at ~85%).
- Ends at ~95% in "Volume".
### Key Observations
- **GPT-4 Dominance**: Consistently outperforms other models, achieving perfect scores in multiple topics.
- **MetaMath-13B Instability**: Dramatic drops (e.g., 0% in Probability) suggest potential weaknesses in probabilistic reasoning.
- **LLaMA2-70B Middle Ground**: Balanced performance but lags behind GPT-4 in critical areas.
- **Topic-Specific Patterns**:
- Geometry topics (e.g., "Circles & sorting") show high accuracy across all models.
- Probability and Statistics topics reveal MetaMath-13B's vulnerabilities.
### Interpretation
The data highlights **GPT-4's superior generalization** in math tasks, likely due to its larger scale and training data. **MetaMath-13B's erratic performance** may stem from specialized training or overfitting to specific problem types. The **0% accuracy in Probability** for MetaMath-13B raises questions about its architectural limitations in handling abstract concepts. LLaMA2-70B's mid-range performance suggests it balances specialization and versatility but lacks GPT-4's robustness.
**Critical Insight**: Model size and training focus significantly impact math task performance, with GPT-4's scale enabling near-perfect accuracy across diverse topics.