TECHNICAL ASSET FINGERPRINT
36abfe92dfdcefff8b2e9a22
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
\n
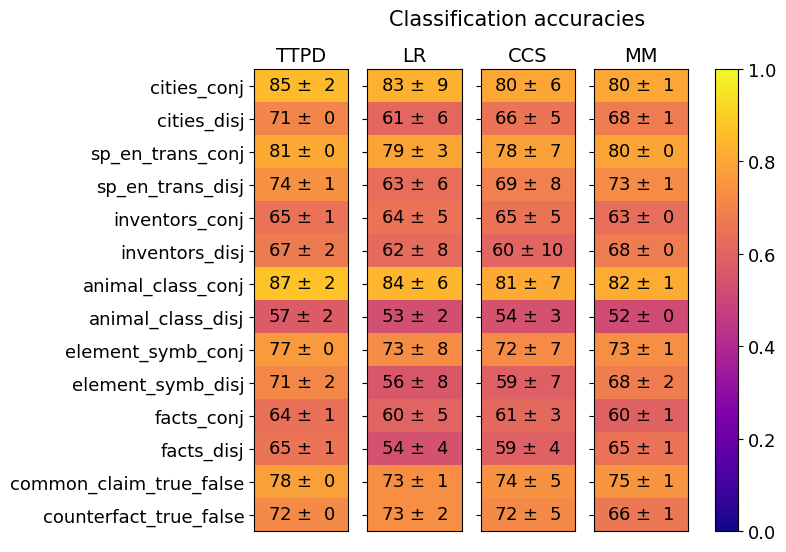
## Heatmap: Classification Accuracies
### Overview
The image is a heatmap titled "Classification accuracies" that displays the performance (accuracy scores with standard deviations) of four different models or methods (TTPD, LR, CCS, MM) across fourteen distinct classification tasks. The tasks are grouped into pairs, often contrasting "conj" (conjunctive) and "disj" (disjunctive) versions of the same domain. Performance is encoded by color, with a legend on the right mapping color to accuracy values from 0.0 (dark purple) to 1.0 (bright yellow).
### Components/Axes
* **Title:** "Classification accuracies" (centered at the top).
* **Columns (Models/Methods):** Four columns labeled from left to right: **TTPD**, **LR**, **CCS**, **MM**.
* **Rows (Tasks):** Fourteen rows, each labeled with a task name. The tasks are, from top to bottom:
1. `cities_conj`
2. `cities_disj`
3. `sp_en_trans_conj`
4. `sp_en_trans_disj`
5. `inventors_conj`
6. `inventors_disj`
7. `animal_class_conj`
8. `animal_class_disj`
9. `element_symb_conj`
10. `element_symb_disj`
11. `facts_conj`
12. `facts_disj`
13. `common_claim_true_false`
14. `counterfact_true_false`
* **Legend/Color Bar:** Positioned vertically on the right side of the heatmap. It is a gradient bar labeled from **0.0** at the bottom (dark purple) to **1.0** at the top (bright yellow), with intermediate ticks at **0.2**, **0.4**, **0.6**, and **0.8**. This bar provides the key for interpreting the cell colors as accuracy scores.
* **Cell Content:** Each cell in the grid contains a numerical accuracy value followed by a "±" symbol and a standard deviation (e.g., `85 ± 2`). The background color of each cell corresponds to its accuracy value according to the legend.
### Detailed Analysis
The following table reconstructs the data presented in the heatmap. Values are accuracy ± standard deviation.
| Task | TTPD | LR | CCS | MM |
| :--- | :--- | :--- | :--- | :--- |
| **cities_conj** | 85 ± 2 | 83 ± 9 | 80 ± 6 | 80 ± 1 |
| **cities_disj** | 71 ± 0 | 61 ± 6 | 66 ± 5 | 68 ± 1 |
| **sp_en_trans_conj** | 81 ± 0 | 79 ± 3 | 78 ± 7 | 80 ± 0 |
| **sp_en_trans_disj** | 74 ± 1 | 63 ± 6 | 69 ± 8 | 73 ± 1 |
| **inventors_conj** | 65 ± 1 | 64 ± 5 | 65 ± 5 | 63 ± 0 |
| **inventors_disj** | 67 ± 2 | 62 ± 8 | 60 ± 10 | 68 ± 0 |
| **animal_class_conj** | 87 ± 2 | 84 ± 6 | 81 ± 7 | 82 ± 1 |
| **animal_class_disj** | 57 ± 2 | 53 ± 2 | 54 ± 3 | 52 ± 0 |
| **element_symb_conj** | 77 ± 0 | 73 ± 8 | 72 ± 7 | 73 ± 1 |
| **element_symb_disj** | 71 ± 2 | 56 ± 8 | 59 ± 7 | 68 ± 2 |
| **facts_conj** | 64 ± 1 | 60 ± 5 | 61 ± 3 | 60 ± 1 |
| **facts_disj** | 65 ± 1 | 54 ± 4 | 59 ± 4 | 65 ± 1 |
| **common_claim_true_false** | 78 ± 0 | 73 ± 1 | 74 ± 5 | 75 ± 1 |
| **counterfact_true_false** | 72 ± 0 | 73 ± 2 | 72 ± 5 | 66 ± 1 |
**Visual Trend Verification per Column (Model):**
* **TTPD (Leftmost column):** Visually the warmest (most yellow/orange) column, indicating generally the highest accuracies. It shows a clear pattern where "conj" tasks (e.g., `cities_conj`, `animal_class_conj`) are significantly warmer (higher accuracy) than their "disj" counterparts.
* **LR (Second column):** Shows more variation, with cooler colors (reds) appearing, especially in "disj" tasks like `animal_class_disj` and `element_symb_disj`. It often has the lowest accuracy in a given row.
* **CCS (Third column):** Similar in tone to LR but often slightly warmer. It exhibits high variance in some cells, indicated by large standard deviations (e.g., `inventors_disj` 60 ± 10).
* **MM (Rightmost column):** Generally performs comparably to or slightly better than LR and CCS, with a few notable exceptions like `counterfact_true_false` where it is the coolest (lowest accuracy).
### Key Observations
1. **Conjunctive vs. Disjunctive Performance Gap:** For nearly every paired task (e.g., `cities_conj` vs. `cities_disj`), the "conj" version has a markedly higher accuracy than the "disj" version across all models. The largest gap appears in `animal_class_conj` (87±2 for TTPD) vs. `animal_class_disj` (57±2 for TTPD).
2. **Model Performance Hierarchy:** TTPD consistently achieves the highest or tied-for-highest accuracy on 13 out of 14 tasks. The only exception is `counterfact_true_false`, where LR (73±2) slightly outperforms TTPD (72±0).
3. **Task Difficulty:** The `animal_class_disj` task appears to be the most challenging, with accuracies ranging from 52±0 (MM) to 57±2 (TTPD). Conversely, `animal_class_conj` is among the easiest, with scores from 81±7 (CCS) to 87±2 (TTPD).
4. **High Variance:** Several cells show high standard deviations, indicating unstable performance across runs or folds. The most extreme example is `inventors_disj` under CCS (60 ± 10).
5. **Outlier:** The `counterfact_true_false` task breaks the general pattern. It is the only task where TTPD is not the top performer, and it's the only task where MM's performance (66±1) is notably lower than the other three models (all 72±0 or higher).
### Interpretation
This heatmap provides a comparative analysis of four models on a suite of classification tasks that likely test reasoning about relationships (conjunctive "and" vs. disjunctive "or") across different knowledge domains (cities, translations, inventors, etc.).
* **What the data suggests:** The consistent performance gap between "conj" and "disj" tasks indicates that disjunctive reasoning is fundamentally harder for these models than conjunctive reasoning. This could be because verifying an "or" condition requires checking multiple potential pathways, whereas an "and" condition is a more straightforward conjunction of facts.
* **Model Relationships:** TTPD's superior performance suggests it has a more robust architecture or training method for these specific types of reasoning tasks. The similarity in performance between LR, CCS, and MM implies they may share underlying methodological limitations.
* **Anomalies and Insights:** The high variance in some cells (e.g., CCS on `inventors_disj`) points to potential instability in the model's application to that specific task. The outlier status of `counterfact_true_false` is particularly interesting. It suggests that reasoning about counterfactuals ("what if not") engages different cognitive or computational mechanisms than reasoning about factual conjunctions/disjunctions, and the models' relative strengths do not transfer cleanly to this domain. This task could be a useful probe for distinguishing model capabilities beyond standard accuracy metrics.
DECODING INTELLIGENCE...