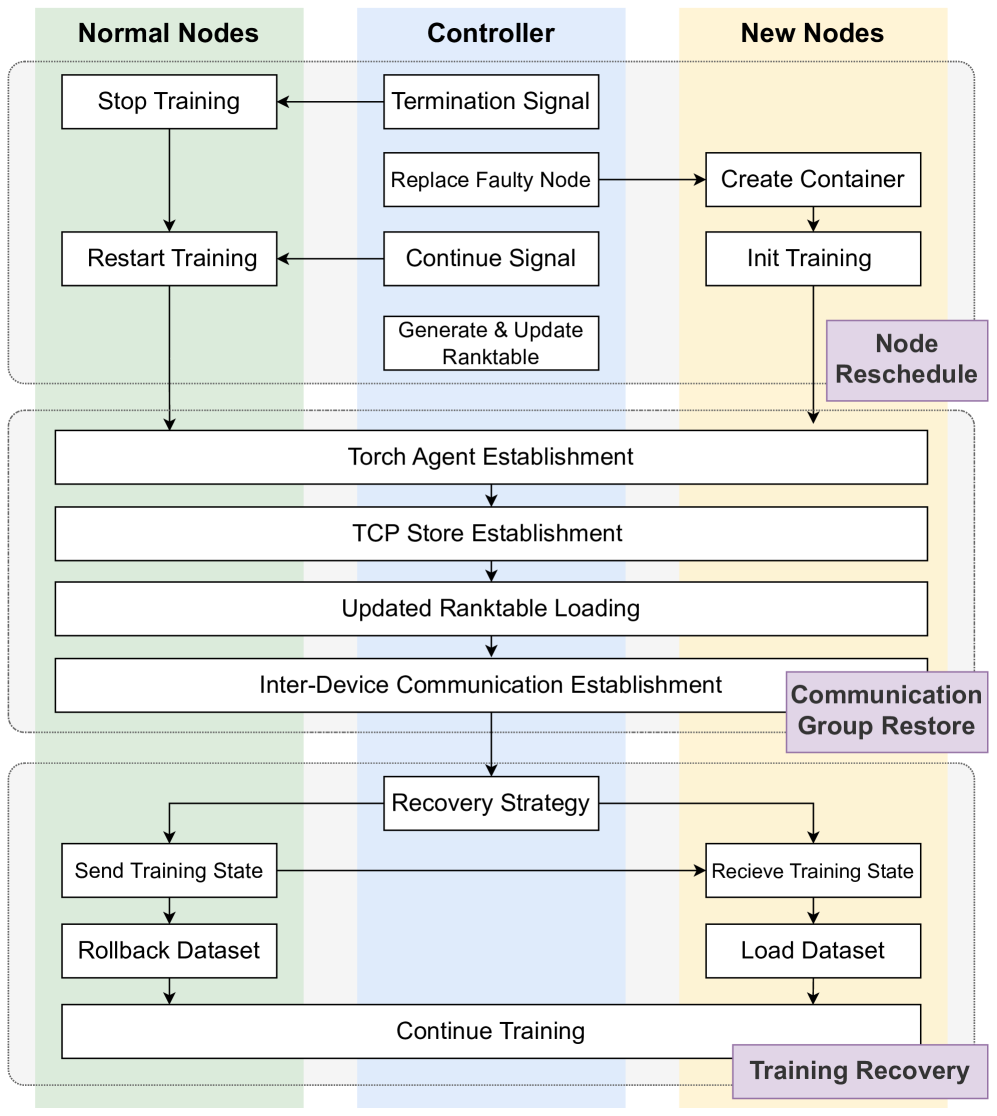
# Technical Document Extraction: Node Rescheduling and Training Recovery Workflow
This document provides a comprehensive extraction of the technical flowchart illustrating the process of node replacement and training recovery in a distributed computing environment.
## 1. System Architecture Overview
The diagram is organized into three vertical columns representing the primary actors/components and three horizontal phases representing the logical stages of the process.
### Vertical Columns (Actors)
* **Normal Nodes (Left, Green Background):** Existing healthy nodes in the cluster.
* **Controller (Center, Blue Background):** The management entity coordinating the recovery.
* **New Nodes (Right, Yellow Background):** Replacement nodes introduced to the cluster.
### Horizontal Phases (Process Stages)
* **Node Reschedule (Top):** Handling the failure and provisioning new resources.
* **Communication Group Restore (Middle):** Re-establishing the network and rank configuration.
* **Training Recovery (Bottom):** Synchronizing state and resuming the workload.
---
## 2. Detailed Component and Flow Analysis
### Phase 1: Node Reschedule
This phase initiates when a node failure is detected.
1. **Controller Actions:**
* Sends a **Termination Signal** to **Normal Nodes**.
* Executes **Replace Faulty Node**, which triggers the creation of a replacement.
* Sends a **Continue Signal** to **Normal Nodes** once the replacement is ready.
* Performs **Generate & Update Ranktable** (internal process).
2. **Normal Nodes Actions:**
* Receive Termination Signal $\rightarrow$ **Stop Training**.
* Receive Continue Signal $\rightarrow$ **Restart Training**.
3. **New Nodes Actions:**
* Triggered by Controller $\rightarrow$ **Create Container**.
* Followed by **Init Training**.
### Phase 2: Communication Group Restore
This phase involves all nodes (Normal and New) and is represented by wide blocks spanning across the columns. The flow is strictly sequential:
1. **Torch Agent Establishment:** Initializing the distributed agents.
2. **TCP Store Establishment:** Setting up the key-value store for distributed coordination.
3. **Updated Ranktable Loading:** Loading the new cluster configuration generated by the Controller in Phase 1.
4. **Inter-Device Communication Establishment:** Finalizing the network layer for data exchange between nodes.
### Phase 3: Training Recovery
This phase focuses on data synchronization and resuming the computational task.
1. **Recovery Strategy (Controller/Global):** The central logic determining how to resume.
2. **Normal Nodes Path:**
* **Send Training State:** Transmits the last known good checkpoint/state to the new nodes.
* **Rollback Dataset:** Reverts the data iterator to the correct position.
3. **New Nodes Path:**
* **Receive Training State:** Accepts the state from Normal Nodes.
* **Load Dataset:** Initializes the data stream.
4. **Final Step (Unified):**
* **Continue Training:** All nodes resume the training process in synchronization.
---
## 3. Textual Transcription
| Category | Transcribed Text |
| :--- | :--- |
| **Headers** | Normal Nodes, Controller, New Nodes |
| **Phase Labels (Purple)** | Node Reschedule, Communication Group Restore, Training Recovery |
| **Process Blocks** | Stop Training, Restart Training, Termination Signal, Replace Faulty Node, Continue Signal, Generate & Update Ranktable, Create Container, Init Training, Torch Agent Establishment, TCP Store Establishment, Updated Ranktable Loading, Inter-Device Communication Establishment, Recovery Strategy, Send Training State, Rollback Dataset, Receive Training State, Load Dataset, Continue Training |
---
## 4. Technical Summary of Logic
The system employs a **Stop-and-Restart** recovery mechanism. The **Controller** acts as the orchestrator, managing the lifecycle of the **New Nodes** and updating the **Ranktable** (the map of node identities). The **Communication Group Restore** phase acts as a synchronization barrier where all nodes must re-initialize their distributed environment (Torch Agent, TCP Store) before the **Training Recovery** phase can synchronize the model state and dataset offsets to ensure training continuity without data corruption or loss of progress.