# Technical Document Extraction: Fault Tolerance and Training Recovery Workflow
## Diagram Overview
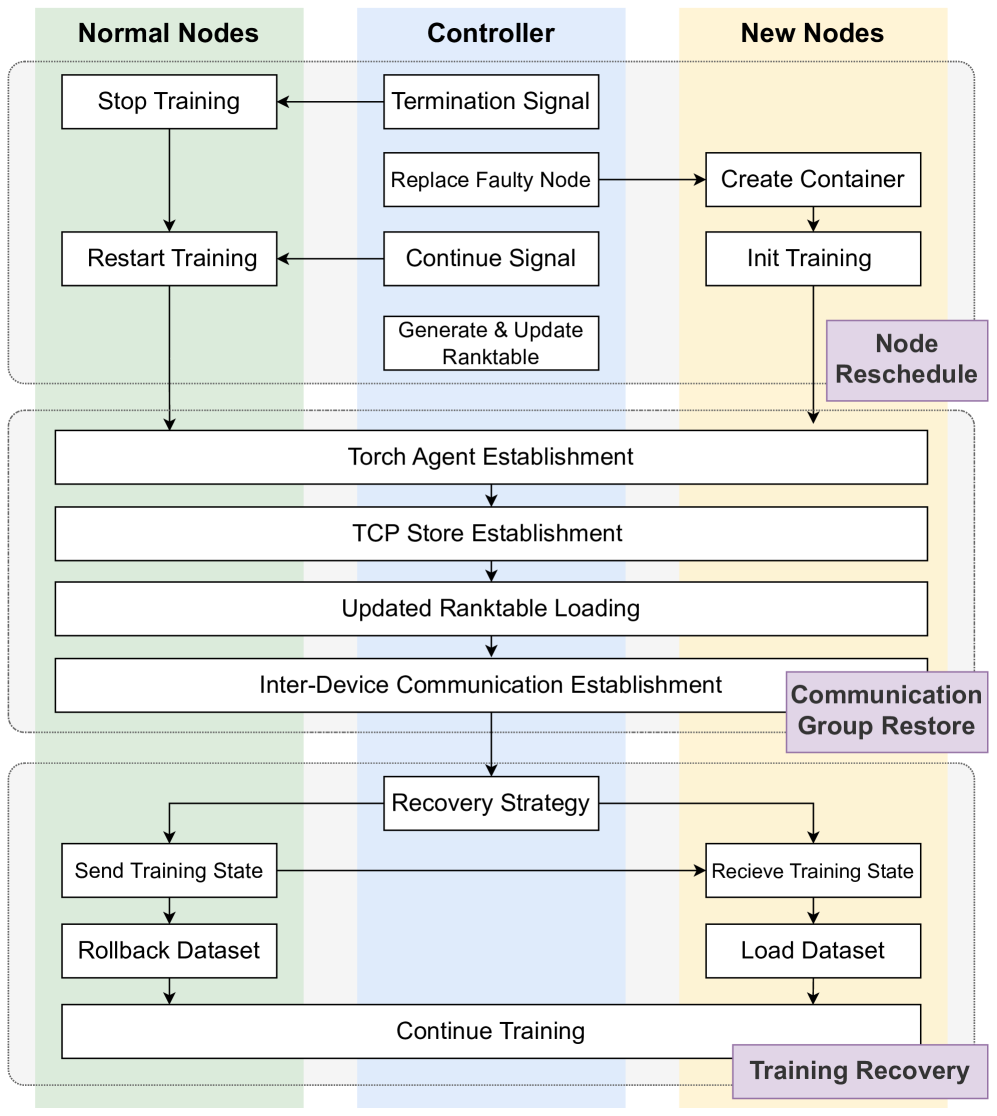
This flowchart illustrates a distributed training system's fault tolerance and recovery mechanisms across three primary components: **Normal Nodes**, **Controller**, and **New Nodes**. The diagram emphasizes process coordination, fault detection, and training state management.
---
## Component Breakdown
### 1. Normal Nodes (Left Section)
- **Processes**:
- **Stop Training** → Triggers `Termination Signal` to Controller
- **Restart Training** → Initiated by `Continue Signal` from Controller
- **Send Training State** → Part of `Recovery Strategy` workflow
- **Rollback Dataset** → Enables `Continue Training` after recovery
### 2. Controller (Center Section)
- **Key Processes**:
- **Termination Signal** → Received from Normal Nodes (Stop Training)
- **Continue Signal** → Sent to Normal Nodes (Restart Training)
- **Replace Faulty Node** → Triggers `Create Container` in New Nodes
- **Generate & Update Ranktable** → Maintains model performance metrics
### 3. New Nodes (Right Section)
- **Processes**:
- **Create Container** → Initiated by Controller's `Replace Faulty Node`
- **Init Training** → Starts training in new containers
- **Load Dataset** → Part of `Training Recovery` workflow
- **Node Reschedule** → Feedback loop from `Load Dataset` to `Init Training`
---
## Inter-Component Workflow
### 1. Fault Detection & Recovery
- **Trigger**: Normal Node detects failure → Sends `Termination Signal`
- **Controller Action**:
- Replaces faulty node via `Replace Faulty Node`
- Generates updated `Ranktable` for performance tracking
- **New Node Action**:
- Creates container (`Create Container`)
- Initializes training (`Init Training`)
### 2. Training State Synchronization
- **Recovery Strategy**:
- Normal Nodes `Send Training State` to Controller
- New Nodes `Receive Training State` from Controller
- Enables `Rollback Dataset` (Normal Nodes) and `Load Dataset` (New Nodes)
- **Outcome**: System `Continue Training` with synchronized state
### 3. Communication Infrastructure
- **Torch Agent Establishment** → Manages distributed training coordination
- **TCP Store Establishment** → Ensures reliable data transfer
- **Inter-Device Communication Establishment** → Facilitates cross-node synchronization
---
## Key Trends and Logic Checks
1. **Fault Propagation Flow**:
- Normal Nodes → Controller (via Termination Signal)
- Controller → New Nodes (via Replace Faulty Node)
- New Nodes → Controller (via Init Training completion)
2. **State Management**:
- Training state is preserved via `Send/Receive Training State` between Normal and New Nodes
- Dataset continuity maintained through `Rollback` (Normal) and `Load` (New) processes
3. **Performance Tracking**:
- `Generate & Update Ranktable` occurs after fault resolution to assess model impact
---
## Spatial Grounding and Component Isolation
- **Normal Nodes** (Left): Focus on training interruption/resumption
- **Controller** (Center): Central decision-making hub for fault handling
- **New Nodes** (Right): Responsible for containerization and retraining
- **Middle Section**: Communication infrastructure (Torch Agent, TCP Store)
- **Bottom Section**: Recovery strategy execution
---
## Critical Observations
1. **Redundancy Mechanism**: New Nodes act as backup capacity during failures
2. **State Preservation**: Training state is explicitly transferred between node types
3. **Automated Recovery**: System self-heals via container replacement and state synchronization
4. **Performance Monitoring**: Ranktable updates ensure quality control post-recovery
---
## Diagram Text Transcription
All textual elements have been extracted and organized above. No non-English text detected. Arrows represent process flow directionality, with labels indicating specific control signals or data transfers.