\n
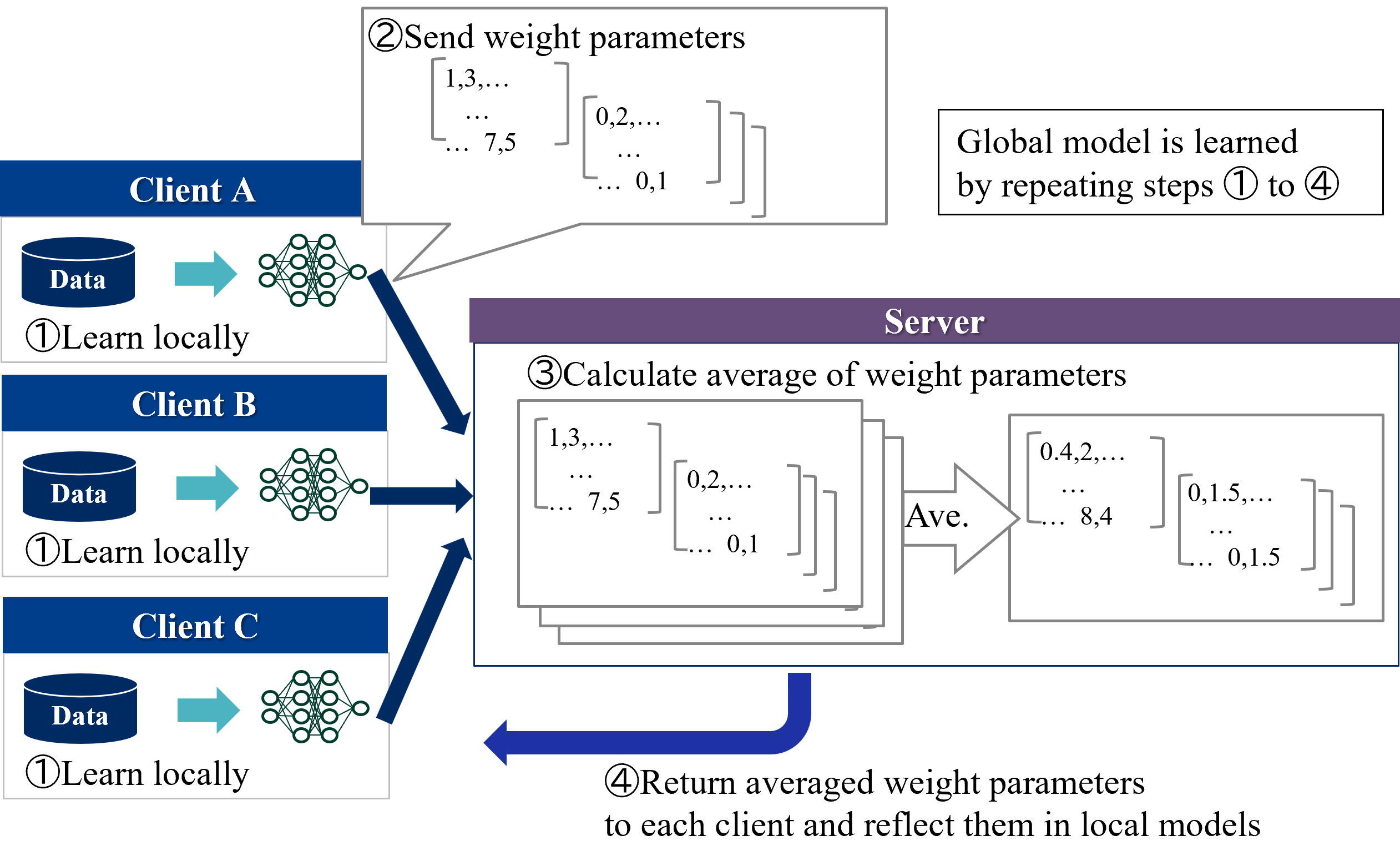
## Diagram: Federated Learning Process
### Overview
This diagram illustrates the process of Federated Learning, where a global model is trained across multiple clients without directly exchanging data. The diagram depicts three clients (A, B, and C) learning locally from their respective data and then communicating weight parameters to a central server for aggregation. The server then returns the averaged weight parameters to the clients, updating their local models. This process is repeated iteratively to improve the global model.
### Components/Axes
The diagram consists of three client nodes (A, B, C) and a central server node. Each client node contains a "Data" block and a "Learn locally" process represented by a neural network icon. Arrows indicate the flow of data and weight parameters. The diagram is numbered 1-4 to indicate the sequence of steps.
### Detailed Analysis or Content Details
**Step 1: Learn Locally**
- Each client (A, B, C) has a "Data" block, which is the input for local learning.
- Each client uses a neural network to "Learn locally" from its data. The neural network is represented by interconnected nodes.
**Step 2: Send Weight Parameters**
- Client A sends weight parameters represented as a matrix: `[1,3,... ... 7,5]`, `[0,2,... ... 0,1]`.
- Client B sends weight parameters represented as a matrix: `[1,3,... ... 7,5]`, `[0,2,... ... 0,1]`.
- Client C sends weight parameters represented as a matrix: `[1,3,... ... 7,5]`, `[0,2,... ... 0,1]`.
- These weight parameters are sent to the server.
**Step 3: Calculate Average of Weight Parameters**
- The server receives weight parameters from all clients.
- The server calculates the average of these parameters.
- The server displays the averaged weight parameters as matrices: `[0,4,2,... ... 8,4]`, `[0,1,5,... ... 0,1,5]`.
- The "Ave." label is placed within the averaging process.
**Step 4: Return Averaged Weight Parameters**
- The server returns the averaged weight parameters to each client.
- The clients update their local models based on the received parameters.
- The curved arrow indicates the return flow of averaged parameters.
**Global Model Learning:**
- A text box on the top-right states: "Global model is learned by repeating steps ① to ④".
### Key Observations
- All clients initially send the same weight parameter matrices.
- The server averages these identical matrices, resulting in an averaged matrix with similar structure.
- The diagram emphasizes the iterative nature of the Federated Learning process.
- The diagram does not provide specific numerical values for the weight parameters beyond the examples given.
### Interpretation
The diagram demonstrates the core principle of Federated Learning: decentralized model training. Each client maintains control over its data, and only model updates (weight parameters) are shared with the server. This approach addresses privacy concerns and enables learning from distributed datasets. The iterative process of local learning and global aggregation allows the model to converge towards a shared understanding without compromising data confidentiality. The repetition of steps 1-4 suggests a continuous improvement cycle, where the global model gradually refines its performance based on the collective knowledge of all clients. The identical initial weight parameters sent by each client may indicate a starting point for the learning process, or a pre-trained model being fine-tuned. The diagram is a conceptual illustration and does not detail the specific algorithms or techniques used for local learning or parameter averaging.