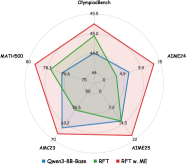
## Radar Chart: Olympiabench
### Overview
The image is a radar chart comparing the performance of three models (Qwen3-8B-Base, RFT, and RFT w. ME) across five different benchmarks: AIME24, AIME25, AMC23, MATH500, and Olympiabench. The chart displays the scores achieved by each model on each benchmark, with higher scores indicating better performance.
### Components/Axes
* **Title:** Olympiabench
* **Axes:** The radar chart has five axes, each representing a different benchmark:
* AIME24 (at approximately 15 degrees)
* AIME25 (at approximately 70 degrees)
* AMC23 (at approximately 140 degrees)
* MATH500 (at approximately 210 degrees)
* Olympiabench (at approximately 300 degrees)
* **Scale:** The radial scale ranges from 0 to 80, with markers at 0, 25, 50, and 75.
* **Legend:** Located at the bottom of the chart:
* Blue: Qwen3-8B-Base
* Green: RFT
* Red: RFT w. ME
### Detailed Analysis
* **Qwen3-8B-Base (Blue):**
* AIME24: Approximately 9.9
* AIME25: Approximately 14.5
* AMC23: Approximately 53.2
* MATH500: Approximately 76.6
* Olympiabench: Approximately 44.6
* **RFT (Green):**
* AIME24: Approximately 6.9
* AIME25: Approximately 7.2
* AMC23: Approximately 38.6
* MATH500: Approximately 79.3
* Olympiabench: Approximately 45.0
* **RFT w. ME (Red):**
* AIME24: Approximately 15
* AIME25: Approximately 20
* AMC23: Approximately 70
* MATH500: Approximately 80
* Olympiabench: Approximately 45.5
### Key Observations
* RFT w. ME (Red) consistently outperforms the other two models across all benchmarks.
* Qwen3-8B-Base (Blue) generally performs better than RFT (Green), except for the MATH500 benchmark.
* All models perform relatively poorly on the AIME24 and AIME25 benchmarks compared to AMC23 and MATH500.
* The performance on Olympiabench is similar across all three models.
### Interpretation
The radar chart provides a visual comparison of the performance of three models on five different benchmarks. The RFT w. ME model demonstrates superior performance across all benchmarks, suggesting that the "ME" component significantly enhances the model's capabilities. The relatively low scores on AIME24 and AIME25 across all models indicate that these benchmarks may be more challenging or require different skills than AMC23 and MATH500. The similar performance on Olympiabench suggests that this benchmark may not be as discriminating between the models as the others. The data suggests that RFT w. ME is the most effective model among the three for the given set of benchmarks.