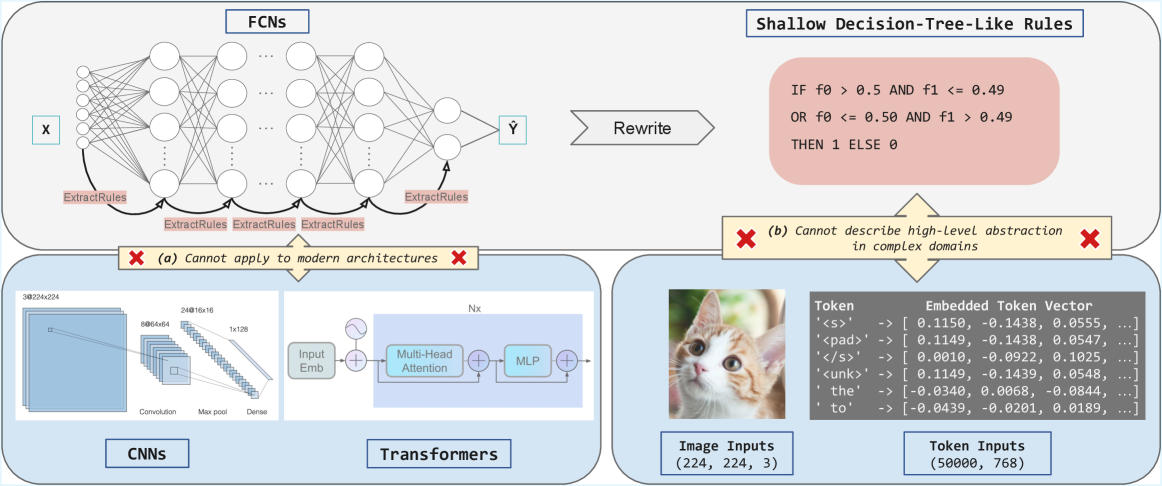
## Diagram: Comparison of Neural Network Architectures and Rule Extraction
### Overview
The image presents a comparison of different neural network architectures (FCNs, CNNs, Transformers) and their ability to be represented by shallow decision-tree-like rules. It highlights the limitations of extracting simple rules from modern architectures.
### Components/Axes
* **Top-Left:** FCNs (Fully Connected Networks)
* Input: X
* Output: Ŷ
* Process: Multiple layers of interconnected nodes.
* "ExtractRules" labels indicate rule extraction at different layers.
* **Top-Right:** Shallow Decision-Tree-Like Rules
* Logic:
```
IF f0 > 0.5 AND f1 <= 0.49
OR f0 <= 0.50 AND f1 > 0.49
THEN 1 ELSE 0
```
* "Rewrite" arrow connects FCNs to the rules.
* **Bottom-Left:** CNNs (Convolutional Neural Networks)
* Input: 3@224x224
* Process: Convolution, Max pool, Dense layers.
* Intermediate Layers: 8@64x64, 24@16x16, 1x128
* **Bottom-Center:** Transformers
* Input: Nx
* Process: Input Emb, Multi-Head Attention, MLP (Multi-Layer Perceptron).
* **Bottom-Right:** Image and Token Inputs
* Image Inputs: (224, 224, 3) - An image of a cat is shown.
* Token Inputs: (50000, 768)
* Example Tokens and Embedded Token Vectors:
* '<s>' -> [0.1150, -0.1438, 0.0555, ...]
* '<pad>' -> [0.1149, -0.1438, 0.0547, ...]
* '</s>' -> [0.0010, -0.0922, 0.1025, ...]
* '<unk>' -> [0.1149, -0.1439, 0.0548, ...]
* 'the' -> [-0.0340, 0.0068, -0.0844, ...]
* 'to' -> [-0.0439, -0.0201, 0.0189, ...]
* **Annotations:**
* Red "X" with text: "(a) Cannot apply to modern architectures" - positioned between FCNs and CNNs/Transformers.
* Red "X" with text: "(b) Cannot describe high-level abstraction in complex domains" - positioned between Shallow Decision-Tree-Like Rules and Image/Token Inputs.
### Detailed Analysis or Content Details
* **FCNs:** The diagram shows a standard fully connected neural network with multiple layers. The "ExtractRules" labels suggest an attempt to extract rules from the network's internal representations.
* **Shallow Decision-Tree-Like Rules:** The rules are simple logical statements based on two features (f0 and f1).
* **CNNs:** The CNN architecture is depicted with convolutional, max pooling, and dense layers, processing an input image of size 3@224x224.
* **Transformers:** The Transformer architecture includes input embedding, multi-head attention, and an MLP, processing an input of size Nx.
* **Image/Token Inputs:** The image input is a 224x224 pixel image with 3 color channels. The token inputs consist of 50000 tokens, each represented by a 768-dimensional vector.
### Key Observations
* FCNs are presented as a model from which rules can be extracted.
* Modern architectures like CNNs and Transformers are difficult to represent with simple rules.
* The diagram highlights the trade-off between model complexity and interpretability.
### Interpretation
The diagram illustrates the challenge of interpreting complex neural networks. While FCNs can be approximated by simple decision rules, modern architectures like CNNs and Transformers are too complex for such representations. This suggests that while these models achieve high performance, understanding their decision-making process is difficult. The annotations emphasize the limitations of applying simple rule extraction techniques to modern architectures and the inability of such rules to capture high-level abstractions in complex domains.