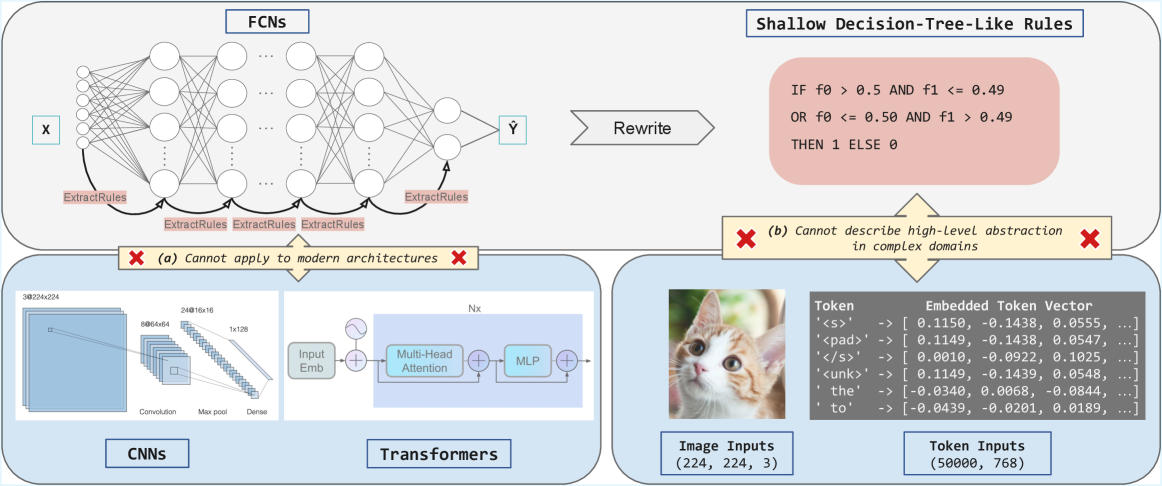
\n
## Diagram: Neural Network Architectures and Rule Extraction
### Overview
This diagram illustrates a comparison of different neural network architectures (FCNs, CNNs, and Transformers) in the context of rule extraction and their limitations. It highlights the challenges of extracting interpretable rules from complex models and contrasts them with shallow decision-tree-like rules. The diagram also shows an example of token embedding with an image of a cat.
### Components/Axes
The diagram is segmented into four main sections:
1. **FCNs (Fully Connected Networks):** Depicts a neural network with input 'X' and output 'Y', with a process labeled "ExtractRules" attempting to derive rules.
2. **CNNs (Convolutional Neural Networks):** Shows a CNN architecture with layers labeled "Convolution," "Max pool," and "Dense," along with input dimensions (64x64x3 to 1x1x16).
3. **Transformers:** Illustrates a Transformer architecture with "Input Emb," "Multi-Head Attention," and "MLP" layers, with an output dimension of 'Nx'.
4. **Shallow Decision-Tree-Like Rules & Token Embedding:** Presents a simple rule-based system and an example of token embedding with an image of a cat.
There are two prominent "X" symbols with annotations:
* **(a) Cannot apply to modern architectures** - associated with the FCN section.
* **(b) Cannot describe high-level abstraction in complex domains** - associated with the token embedding section.
### Detailed Analysis or Content Details
**FCNs:**
* Input: X
* Output: Y
* Process: "ExtractRules" is applied multiple times.
* Annotation: "(a) Cannot apply to modern architectures"
**CNNs:**
* Input Dimensions: 64x64x3
* Layer 1: Convolution (output size not explicitly stated)
* Layer 2: Max pool (output size not explicitly stated)
* Layer 3: Dense (output size: 1x1x16)
**Transformers:**
* Input: Input Embedding (Input Emb)
* Layer 1: Multi-Head Attention
* Layer 2: MLP (Multi-Layer Perceptron)
* Output Dimension: Nx
**Shallow Decision-Tree-Like Rules:**
* Rule 1: IF f0 > 0.5 AND f1 < 0.49 OR f0 <= 0.50 AND f1 > 0.49 THEN 1 ELSE 0
* Annotation: "(b) Cannot describe high-level abstraction in complex domains"
**Token Embedding:**
* Image Input Dimensions: 224x224x3
* Token Input Dimensions: (50000, 768)
* Example Token Embeddings:
* `<bos>` -> [0.1150, -0.1438, 0.0555, ...]
* `<pad>` -> [0.1149, -0.1438, 0.0547, ...]
* `</s>` -> [0.0010, -0.0922, 0.1025, ...]
* `<unk>` -> [0.1149, -0.1439, 0.0548, ...]
* `the` -> [-0.0340, -0.0069, -0.0844, ...]
* `to` -> [-0.0439, -0.0201, 0.0189, ...]
### Key Observations
* The diagram suggests that extracting rules from FCNs is problematic for modern architectures.
* CNNs and Transformers are presented as more complex architectures.
* The token embedding example demonstrates the high dimensionality of token representations (768 dimensions).
* The annotation "(b)" indicates that simple rules struggle to capture the complexity of high-level abstractions.
* The image of the cat is used to illustrate the concept of image inputs and their corresponding token embeddings.
### Interpretation
The diagram illustrates the trade-off between model complexity and interpretability. While simpler models like FCNs might be easier to analyze, they are often insufficient for complex tasks. More powerful architectures like CNNs and Transformers can achieve higher accuracy but are more difficult to understand and explain. The rule extraction attempts from FCNs are deemed inadequate for modern architectures, and even shallow decision-tree-like rules struggle to capture the nuances of complex data representations, as demonstrated by the token embedding example. The diagram highlights the ongoing challenge of making deep learning models more transparent and interpretable. The inclusion of the cat image and token embedding example suggests a focus on natural language processing and computer vision applications. The dimensions provided for image and token inputs give a sense of the scale of data involved in these tasks.