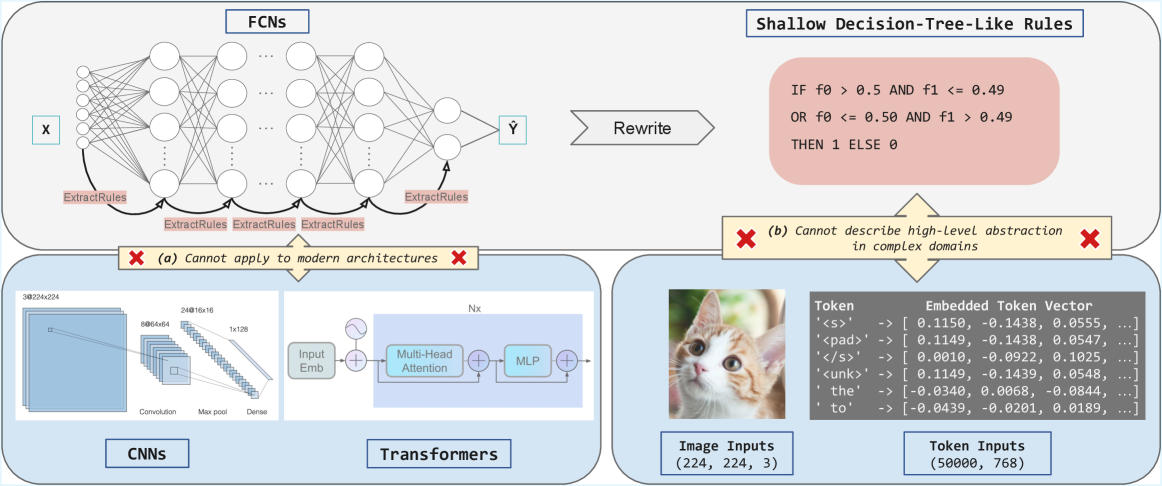
## [Technical Diagram]: Limitations of Rule Extraction from Neural Networks
### Overview
The image is a technical diagram illustrating the challenges of extracting interpretable rules from neural networks, comparing **Fully Connected Networks (FCNs)** with modern architectures (CNNs, Transformers) and complex data domains (images, text tokens). It highlights two key limitations of shallow rule extraction.
### Components/Sections
The diagram is divided into three interconnected sections:
#### 1. Top Section: FCNs and Shallow Rule Extraction
- **FCNs Diagram**: A neural network with input \( \boldsymbol{X} \), hidden layers, and output \( \boldsymbol{\hat{Y}} \). Arrows labeled *“ExtractRules”* point from hidden layers to a box of *“Shallow Decision-Tree-Like Rules”*.
- **Shallow Rules Box**: Contains a binary rule:
*“IF f0 > 0.5 AND f1 <= 0.49 OR f0 <= 0.50 AND f1 > 0.49 THEN 1 ELSE 0”*
- **Limitation (a)**: A red “X” with text: *“(a) Cannot apply to modern architectures”* (links to the bottom-left section).
#### 2. Bottom-Left Section: Modern Architectures (CNNs, Transformers)
- **CNNs**: A diagram of a Convolutional Neural Network with layers:
- Convolution: `3@224x224` (3 channels, 224×224 spatial dimensions).
- Max pool: `8@64x64` (8 channels, 64×64 spatial dimensions).
- Dense: `24@16x16` (24 channels, 16×16 spatial dimensions) → `1x128` (dense layer).
- **Transformers**: A diagram of a Transformer block with:
- *“Input Emb”* (input embedding), *“Multi-Head Attention”*, *“MLP”* (multi-layer perceptron), and *“Nx”* (indicating multiple stacked layers).
- **Limitation (a)**: Red “X” with text: *“(a) Cannot apply to modern architectures”* (connects to the top FCN section).
#### 3. Bottom-Right Section: Complex Domains (Image, Token Inputs)
- **Image Inputs**: A cat image labeled *“Image Inputs (224, 224, 3)”* (dimensions: height, width, color channels).
- **Token Inputs**: A table with the following data:
| Token | Embedded Token Vector |
|-------|-----------------------|
| `<s>` | [0.1150, -0.1438, 0.0555, ...] |
| `<pad>` | [0.1149, -0.1438, 0.0547, ...] |
| `</s>` | — |
| `<unk>` | — |
| `the` | — |
| `to` | — |
*Note: Numerical vectors are provided for `<s>` and `<pad>` as examples; other tokens have similar embedded representations.*
- **Limitation (b)**: A red “X” with text: *“(b) Cannot describe high-level abstraction in complex domains”* (points to the token/image inputs).
### Detailed Analysis
- **FCNs vs. Modern Architectures**: Shallow rules (from FCNs) fail for CNNs/Transformers (limitation a) because these architectures use hierarchical, high-dimensional representations (e.g., CNNs for images, Transformers for sequences) that shallow rules cannot capture.
- **Complex Domains**: Image (224×224×3) and token (50,000 tokens, 768-dimensional embeddings) inputs are high-dimensional and require deep abstraction. Shallow rules (e.g., the binary rule) cannot model the nuanced patterns in these domains (limitation b).
- **Token Embeddings**: The embedded token vectors show how text tokens are represented numerically (e.g., `<s>` and `<pad>` have similar vectors, while `the` and `to` differ), illustrating the complexity of text representation.
### Key Observations
- **Limitation (a)**: Rule extraction from simple FCNs (shallow rules) is incompatible with modern architectures (CNNs, Transformers) due to their complex, hierarchical structures.
- **Limitation (b)**: Shallow rules cannot capture high-level abstractions in complex domains (images, text), where data requires deep, context-aware understanding.
- **Token Embeddings**: The numerical vectors for tokens (e.g., `<s>`, `the`) demonstrate how text is embedded in a vector space, highlighting the complexity of text representation.
### Interpretation
This diagram underscores a critical challenge in deep learning: **interpretable rule extraction** (e.g., shallow decision trees) works for simple FCNs but fails for modern architectures (CNNs, Transformers) and complex data (images, text). Shallow rules lack the expressivity to model hierarchical, high-dimensional representations, emphasizing the need for advanced interpretability methods (e.g., attention mechanisms, concept-based explanations) to bridge the gap between model complexity and human understanding. The image and token inputs illustrate that complex data demands deeper abstraction than shallow rules can provide, driving research into more robust interpretability techniques.
(Note: All text and labels are transcribed directly from the image. The diagram uses visual cues (red “X”s, arrows) to emphasize limitations, and the token embedding table provides concrete examples of text representation in vector space.)