\n
## Bar and Line Chart: LLM Performance vs. APTPU Modules & Model Comparison
### Overview
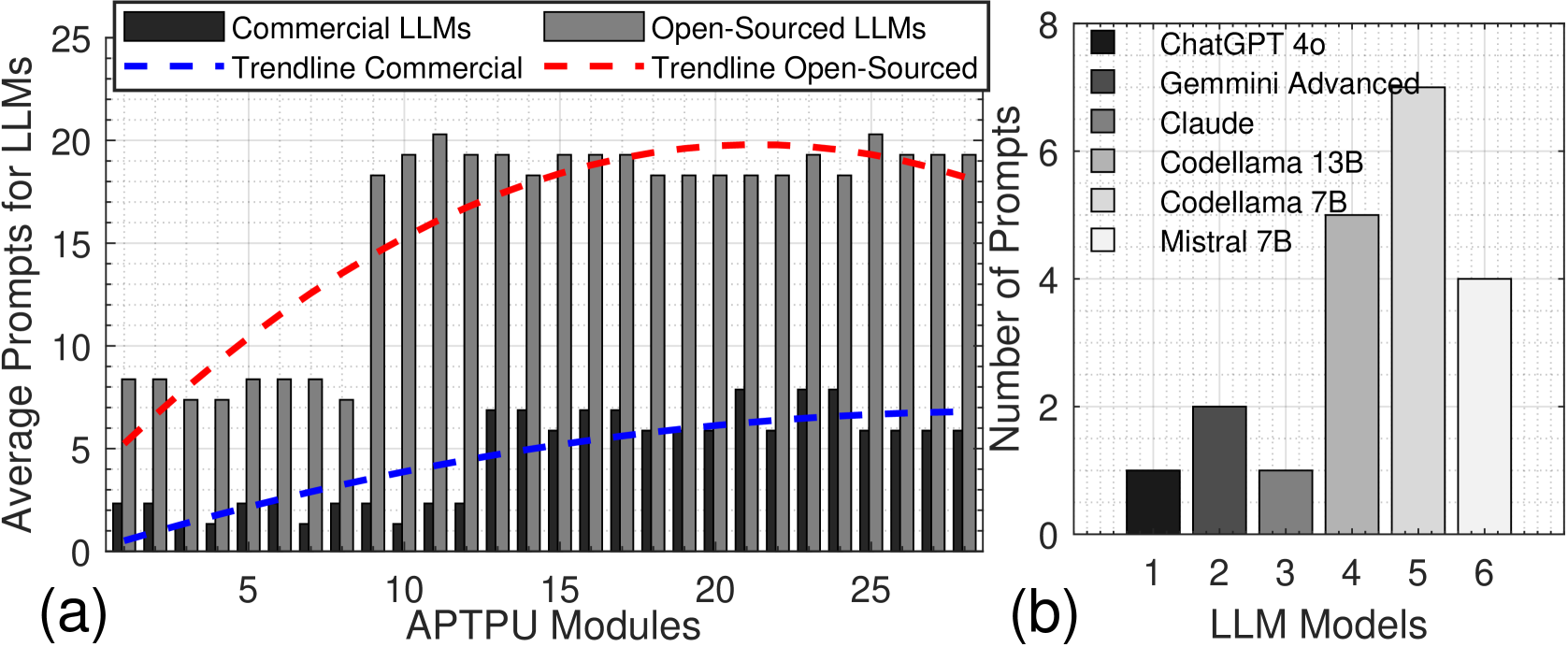
The image presents two charts side-by-side. Chart (a) is a bar chart with overlaid line graphs, comparing the average prompts for Commercial and Open-Sourced LLMs against the number of APTPU Modules. Chart (b) is a bar chart showing the number of prompts for different LLM models.
### Components/Axes
**Chart (a):**
* **X-axis:** APTPU Modules, ranging from 0 to 30, with markers at 5, 10, 15, 20, 25.
* **Y-axis:** Average Prompts for LLMs, ranging from 0 to 25.
* **Data Series:**
* Commercial LLMs (represented by dark gray bars)
* Open-Sourced LLMs (represented by light gray bars)
* Trendline Commercial (represented by a solid blue dashed line)
* Trendline Open-Sourced (represented by a solid red dashed line)
* **Legend:** Located in the top-left corner, clearly labeling each data series with corresponding colors.
**Chart (b):**
* **X-axis:** LLM Models, labeled 1 to 6.
* **Y-axis:** Number of Prompts, ranging from 0 to 8.
* **Data Series:**
* ChatGPT 4o (represented by black bars)
* Gemmini Advanced (represented by dark gray bars)
* Claude (represented by light gray bars)
* Codellama 13B (represented by white bars)
* Codellama 7B (represented by light blue bars)
* Mistral 7B (represented by light green bars)
* **Legend:** Located in the top-right corner, clearly labeling each data series with corresponding colors.
### Detailed Analysis or Content Details
**Chart (a):**
The dark gray bars (Commercial LLMs) generally show higher average prompts than the light gray bars (Open-Sourced LLMs) across all APTPU module values.
* At 0 APTPU Modules: Commercial LLMs ≈ 2 prompts, Open-Sourced LLMs ≈ 1 prompt.
* At 5 APTPU Modules: Commercial LLMs ≈ 8 prompts, Open-Sourced LLMs ≈ 10 prompts.
* At 10 APTPU Modules: Commercial LLMs ≈ 11 prompts, Open-Sourced LLMs ≈ 17 prompts.
* At 15 APTPU Modules: Commercial LLMs ≈ 14 prompts, Open-Sourced LLMs ≈ 19 prompts.
* At 20 APTPU Modules: Commercial LLMs ≈ 16 prompts, Open-Sourced LLMs ≈ 20 prompts.
* At 25 APTPU Modules: Commercial LLMs ≈ 18 prompts, Open-Sourced LLMs ≈ 18 prompts.
The blue dashed line (Trendline Commercial) shows an upward trend initially, then plateaus around 16-18 prompts. The red dashed line (Trendline Open-Sourced) shows a more pronounced upward trend, peaking around 20 prompts, then decreasing slightly.
**Chart (b):**
* LLM Model 1 (ChatGPT 4o): ≈ 7 prompts.
* LLM Model 2 (Gemmini Advanced): ≈ 6 prompts.
* LLM Model 3 (Claude): ≈ 2 prompts.
* LLM Model 4 (Codellama 13B): ≈ 2 prompts.
* LLM Model 5 (Codellama 7B): ≈ 1 prompt.
* LLM Model 6 (Mistral 7B): ≈ 1 prompt.
### Key Observations
* In Chart (a), Open-Sourced LLMs initially outperform Commercial LLMs in terms of average prompts at lower APTPU module counts, but this advantage diminishes and reverses as the number of modules increases.
* The trendlines in Chart (a) suggest diminishing returns for both Commercial and Open-Sourced LLMs as the number of APTPU modules increases.
* In Chart (b), ChatGPT 4o and Gemmini Advanced receive significantly more prompts than the other models. Claude, Codellama 13B, Codellama 7B, and Mistral 7B receive a relatively low number of prompts.
### Interpretation
The data suggests a relationship between the number of APTPU modules and the performance (measured by average prompts) of LLMs. Initially, Open-Sourced LLMs may be more efficient with fewer modules, but Commercial LLMs scale better with increased resources. The trendlines indicate that there's a point of diminishing returns, where adding more modules doesn't significantly improve performance.
Chart (b) highlights the popularity or usage of different LLM models. ChatGPT 4o and Gemmini Advanced are clearly the most frequently used models in this dataset, while the others are used much less often. This could be due to factors such as model capabilities, accessibility, or cost.
The combination of these two charts provides insights into the trade-offs between resource allocation (APTPU modules) and model choice when deploying LLMs. It suggests that optimizing both the hardware infrastructure and the model selection is crucial for achieving optimal performance. The difference in prompt numbers between models could be due to a variety of factors, including model quality, task suitability, and user preference.