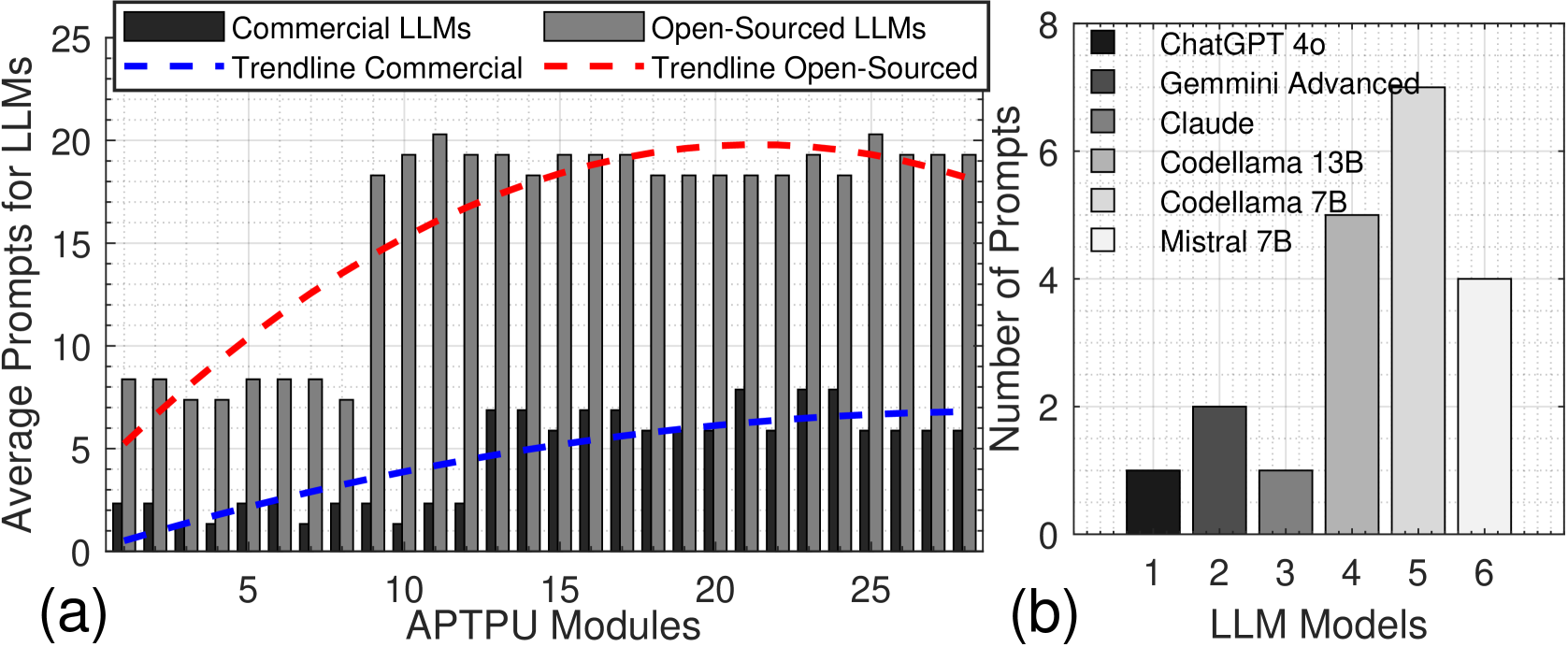
## [Chart Type]: Comparative Bar Charts of LLM Prompt Requirements
### Overview
The image contains two distinct bar charts, labeled (a) and (b), presented side-by-side. Chart (a) compares the average number of prompts required for Commercial versus Open-Sourced Large Language Models (LLMs) across a series of "APTPU Modules." Chart (b) provides a breakdown of the number of prompts for six specific LLM models. The overall theme is an analysis of prompt efficiency or complexity across different LLM types and specific models.
### Components/Axes
**Chart (a) - Left Panel:**
* **Title/Label:** (a) is positioned at the bottom-left corner.
* **X-Axis:** Labeled "APTPU Modules". The axis is marked with major ticks at 0, 5, 10, 15, 20, and 25. There are 25 distinct module positions represented by paired bars.
* **Y-Axis:** Labeled "Average Prompts for LLMs". The scale runs from 0 to 25, with major ticks at intervals of 5.
* **Legend:** Positioned at the top of the chart.
* **Black Square:** "Commercial LLMs"
* **Gray Square:** "Open-Sourced LLMs"
* **Blue Dashed Line:** "Trendline Commercial"
* **Red Dashed Line:** "Trendline Open-Sourced"
**Chart (b) - Right Panel:**
* **Title/Label:** (b) is positioned at the bottom-left corner of its panel.
* **X-Axis:** Labeled "LLM Models". The axis is marked with numbers 1 through 6, corresponding to specific models listed in the legend.
* **Y-Axis:** Labeled "Number of Prompts". The scale runs from 0 to 8, with major ticks at intervals of 2.
* **Legend:** Positioned inside the chart area, top-right. It maps numbers to specific model names:
1. **Black Square:** ChatGPT 4o
2. **Dark Gray Square:** Gemini Advanced
3. **Medium Gray Square:** Claude
4. **Light Gray Square:** Codellama 13B
5. **Very Light Gray Square:** Codellama 7B
6. **White Square:** Mistral 7B
### Detailed Analysis
**Chart (a) Data & Trends:**
* **Commercial LLMs (Black Bars):** The values are consistently low across all APTPU Modules. They start near 0-1 prompts for modules 1-3, rise slightly to approximately 2-3 prompts by module 10, and show a very gradual, shallow upward trend, ending at approximately 6-7 prompts by module 25. The blue dashed trendline confirms this slow, linear increase.
* **Open-Sourced LLMs (Gray Bars):** The values are significantly higher and show a distinct pattern.
* **Modules 1-9:** Values fluctuate between approximately 7 and 9 prompts.
* **Module 10:** A sharp increase occurs, jumping to approximately 18 prompts.
* **Modules 11-25:** Values plateau at a high level, mostly ranging between 18 and 21 prompts, with a slight peak around module 12 (~21) and module 24 (~21). The red dashed trendline shows a steep increase from module 1 to about module 15, after which it flattens, indicating the plateau.
* **Spatial Relationship:** For every module, the gray bar (Open-Sourced) is substantially taller than the black bar (Commercial). The gap between them widens dramatically after module 9.
**Chart (b) Data:**
* **Model 1 (ChatGPT 4o):** Approximately 1 prompt.
* **Model 2 (Gemini Advanced):** Approximately 2 prompts.
* **Model 3 (Claude):** Approximately 1 prompt.
* **Model 4 (Codellama 13B):** Approximately 5 prompts.
* **Model 5 (Codellama 7B):** Approximately 7 prompts (the highest value in this chart).
* **Model 6 (Mistral 7B):** Approximately 4 prompts.
### Key Observations
1. **Major Disparity:** The most striking observation is the large and consistent gap between Open-Sourced and Commercial LLMs in chart (a). Open-sourced models require, on average, 2-3 times more prompts across the measured APTPU Modules.
2. **Phase Change in Open-Sourced Data:** There is a clear discontinuity or "phase change" in the open-sourced data around APTPU Module 10, where the average prompt count more than doubles and then stabilizes at this new, higher level.
3. **Model-Specific Performance:** Chart (b) reveals significant variation among individual models. The two Codellama models (7B and 13B) require notably more prompts than the commercial models (ChatGPT 4o, Gemini Advanced, Claude) and Mistral 7B. Codellama 7B is the most prompt-intensive model shown.
4. **Trendline Confirmation:** The trendlines in chart (a) visually summarize the core finding: a slow, linear increase for commercial models versus a rapid initial increase followed by a high plateau for open-sourced models.
### Interpretation
The data suggests a fundamental difference in either the **capability** or the **interaction paradigm** between the tested Commercial and Open-Sourced LLMs within the context of "APTPU Modules."
* **Efficiency vs. Complexity:** Commercial LLMs appear to be more "prompt-efficient," achieving their outputs with fewer instructions or iterations. This could indicate more advanced instruction-following capabilities, better alignment, or a more integrated system design.
* **The "Module 10" Threshold:** The sharp jump for open-sourced models at module 10 implies a critical point where the task complexity or the nature of the APTPU Module changes in a way that disproportionately challenges these models. They may require more iterative prompting, clarification, or error correction to handle the increased complexity.
* **Model Size vs. Performance:** Interestingly, in chart (b), the smaller Codellama 7B model requires *more* prompts than its larger 13B counterpart. This could suggest that for this specific task, raw model size isn't the only factor; architecture, training data, or fine-tuning might play a larger role in prompt efficiency. The commercial models (ChatGPT, Gemini, Claude) cluster at the low end of the prompt scale, reinforcing the trend seen in chart (a).
**In summary, the charts provide evidence that, for the evaluated tasks (APTPU Modules), commercial LLMs operate with significantly greater prompt efficiency than open-sourced alternatives, which exhibit a distinct two-phase behavior of moderate then high prompt dependency.**