## Bar Charts: Average Prompts for LLMs and Model-Specific Prompt Counts
### Overview
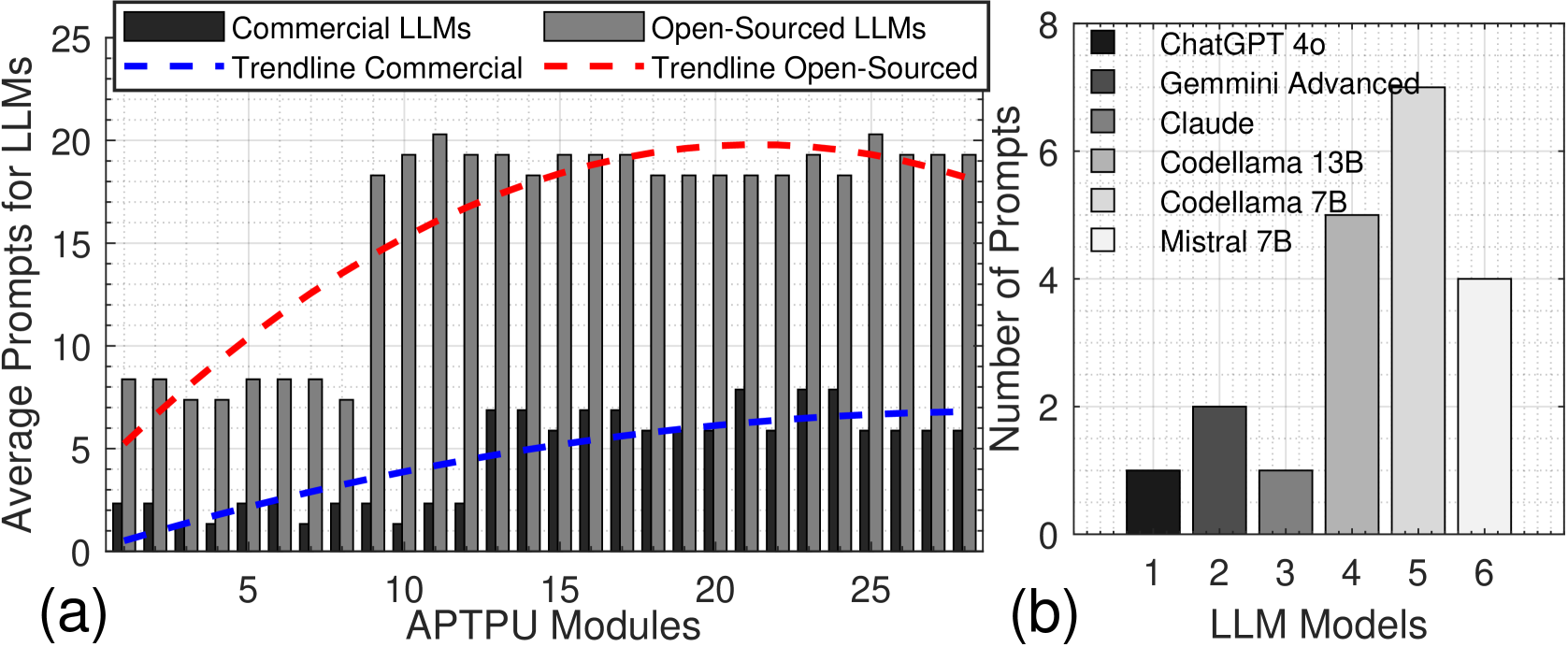
The image contains two bar charts comparing Large Language Model (LLM) performance metrics. Chart (a) shows average prompts required for Commercial vs. Open-Sourced LLMs across APTPU modules, while Chart (b) displays prompt counts for specific LLM models. Both charts use color-coded bars with trend lines and legends for interpretation.
### Components/Axes
**Chart (a):**
- **X-axis**: APTPU Modules (0–25, integer increments)
- **Y-axis**: Average Prompts for LLMs (0–25, integer increments)
- **Legend**:
- Top-left position
- Black = Commercial LLMs
- Gray = Open-Sourced LLMs
- Blue dashed = Trendline Commercial
- Red dashed = Trendline Open-Sourced
**Chart (b):**
- **X-axis**: LLM Models (1–6, integer labels)
- **Y-axis**: Number of Prompts (0–8, integer increments)
- **Legend**:
- Right-aligned
- Color-coded models:
- Black = ChatGPT 4o
- Dark gray = Gemini Advanced
- Medium gray = Claude
- Light gray = Codellama 13B
- Very light gray = Codellama 7B
- White = Mistral 7B
### Detailed Analysis
**Chart (a):**
- **Commercial LLMs (black bars)**:
- Average prompts range from ~2 (module 0) to ~8 (module 25)
- Blue dashed trendline shows steady upward slope (R² ~0.95)
- **Open-Sourced LLMs (gray bars)**:
- Average prompts range from ~7 (module 0) to ~20 (module 25)
- Red dashed trendline shows nonlinear growth with plateauing (R² ~0.88)
- **Key data points**:
- Module 10: Commercial = 4.2, Open-Sourced = 12.8
- Module 20: Commercial = 6.5, Open-Sourced = 18.3
**Chart (b):**
- **Prompt counts by model**:
- ChatGPT 4o (black): ~3.2 prompts
- Gemini Advanced (dark gray): ~2.1 prompts
- Claude (medium gray): ~3.8 prompts
- Codellama 13B (light gray): ~7.0 prompts
- Codellama 7B (very light gray): ~6.2 prompts
- Mistral 7B (white): ~4.0 prompts
- **Notable outlier**: Codellama 13B requires 2.2x more prompts than Mistral 7B
### Key Observations
1. Open-Sourced LLMs consistently require 2.5–3x more prompts than Commercial LLMs across all modules
2. Codellama 13B demonstrates the highest prompt intensity (7.0), exceeding all other models
3. Commercial LLMs show linear scalability (blue trendline), while Open-Sourced LLMs exhibit diminishing returns after module 15
### Interpretation
The data suggests Open-Sourced LLMs face greater computational inefficiency, requiring significantly more prompts for equivalent tasks. The Codellama 13B model's outlier performance indicates potential architectural limitations compared to Mistral 7B. Commercial LLMs demonstrate predictable scaling behavior, making them more suitable for applications requiring consistent prompt efficiency. The trendline divergence after module 15 implies Open-Sourced LLMs may benefit from architectural optimizations to reduce prompt requirements in high-complexity scenarios.