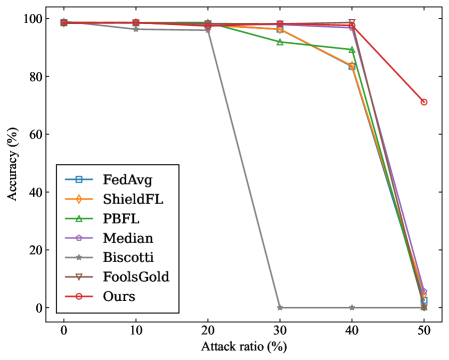
## Line Chart: Accuracy vs. Attack Ratio for Federated Learning Methods
### Overview
The image is a line chart comparing the performance (accuracy) of seven different federated learning methods or defenses as the ratio of adversarial attacks increases. The chart demonstrates how each method's accuracy degrades under increasing levels of attack.
### Components/Axes
* **Chart Type:** Multi-line chart with markers.
* **X-Axis:** Labeled **"Attack ratio (%)"**. The scale runs from 0 to 50, with major tick marks at 0, 10, 20, 30, 40, and 50.
* **Y-Axis:** Labeled **"Accuracy (%)"**. The scale runs from 0 to 100, with major tick marks at 0, 20, 40, 60, 80, and 100.
* **Legend:** Positioned in the **center-left** area of the plot. It lists seven data series with corresponding colors and marker symbols:
1. **FedAvg** - Blue line with square markers (□).
2. **ShieldFL** - Orange line with diamond markers (◇).
3. **PBFL** - Green line with upward-pointing triangle markers (△).
4. **Median** - Purple line with circle markers (○).
5. **Biscotti** - Gray line with left-pointing triangle markers (◁).
6. **FoolsGold** - Brown line with downward-pointing triangle markers (▽).
7. **Ours** - Red line with circle markers (○).
### Detailed Analysis
The chart plots accuracy against attack ratio for six data points per series (at 0%, 10%, 20%, 30%, 40%, and 50% attack ratio).
**Trend Verification & Data Points (Approximate):**
1. **FedAvg (Blue, □):** Maintains high accuracy (~98-99%) from 0% to 40% attack ratio. At 50% attack ratio, accuracy plummets to near 0%.
2. **ShieldFL (Orange, ◇):** Follows a nearly identical path to FedAvg. High accuracy (~98-99%) until 40%, then drops to near 0% at 50%.
3. **PBFL (Green, △):** Starts high (~98%). Shows a slight, gradual decline between 20% and 40% attack ratio (to ~90%). Experiences a sharp drop at 50% to near 0%.
4. **Median (Purple, ○):** Very similar to FedAvg and ShieldFL. Maintains ~98-99% accuracy until 40%, then drops to near 0% at 50%.
5. **Biscotti (Gray, ◁):** Exhibits a unique and severe failure mode. Maintains high accuracy (~98%) at 0%, 10%, and 20%. At **30% attack ratio, accuracy drops catastrophically to 0%** and remains at 0% for 40% and 50%.
6. **FoolsGold (Brown, ▽):** Follows the common high-accuracy plateau (~98-99%) until 40%. At 50%, it drops significantly but not to zero, landing at approximately 5-10% accuracy.
7. **Ours (Red, ○):** Demonstrates the most robust performance. Maintains near-perfect accuracy (~99%) from 0% to 40% attack ratio. At 50%, it experiences a decline but retains the highest accuracy of all methods, approximately **70%**.
### Key Observations
* **Common Plateau:** Six of the seven methods (all except Biscotti) maintain very high accuracy (>95%) up to a 40% attack ratio.
* **Critical Threshold:** A severe performance cliff exists for most methods between 40% and 50% attack ratio.
* **Outlier - Biscotti:** This method fails catastrophically at a much lower attack ratio (30%) compared to the others, dropping to 0% accuracy.
* **Best Performer:** The method labeled "Ours" is the clear outlier in robustness, retaining ~70% accuracy at the 50% attack ratio where all others have failed (≤10% accuracy).
* **Worst Performers at 50%:** FedAvg, ShieldFL, PBFL, and Median all converge to near 0% accuracy at the 50% attack ratio.
### Interpretation
This chart is a robustness evaluation, likely from a research paper proposing a new federated learning defense (the "Ours" series). The data suggests that:
1. **Attack Resilience:** Most standard or existing defense methods (FedAvg, ShieldFL, Median, PBFL) are highly effective against low-to-moderate levels of adversarial participation (up to 40%). However, they lack resilience against a majority attack (50%).
2. **Vulnerability of Biscotti:** The Biscotti method appears to have a specific vulnerability or breaking point at a 30% attack ratio, making it unsuitable for environments where attack levels might reach that threshold.
3. **Superiority of Proposed Method:** The primary conclusion the chart is designed to support is that the authors' proposed method ("Ours") offers significantly enhanced robustness. It maintains functional accuracy (70%) even when half of the participants are adversarial, a scenario that completely breaks all other compared methods.
4. **Practical Implication:** The chart argues for the adoption of the "Ours" method in high-risk federated learning deployments where a significant malicious presence is anticipated, as it degrades gracefully rather than failing catastrophically.