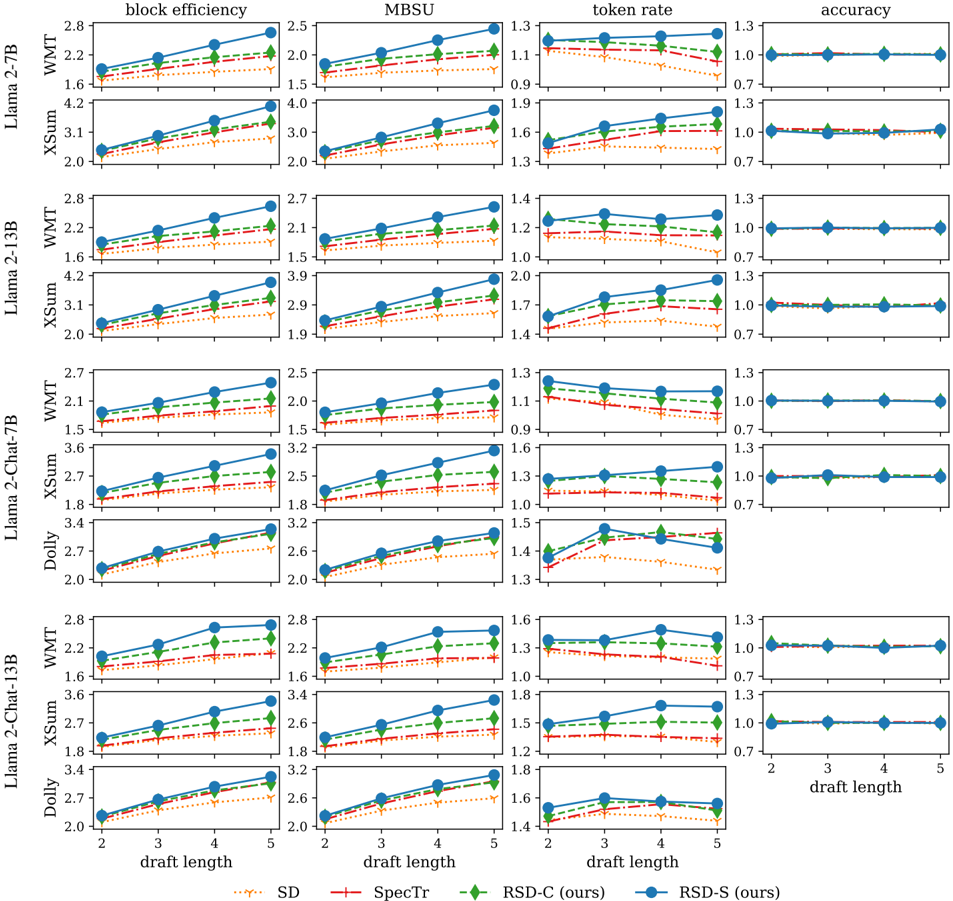
## Line Chart Grid: Performance Metrics of Speculative Decoding Methods
### Overview
The image is a grid of 28 line charts arranged in 7 rows and 4 columns. It compares the performance of four speculative decoding methods (SD, SpecTr, RSD-C, RSD-S) across four metrics (block efficiency, MBSU, token rate, accuracy) for different combinations of Llama-2 models and datasets. The x-axis for all charts is "draft length" (values: 2, 3, 4, 5).
### Components/Axes
* **Columns (Metrics):**
1. **block efficiency** (y-axis label): Measures efficiency, scale varies by model/dataset.
2. **MBSU** (y-axis label): Unknown acronym, scale varies by model/dataset.
3. **token rate** (y-axis label): Measures token generation rate, scale varies by model/dataset.
4. **accuracy** (y-axis label): All charts show a scale from 0.7 to 1.3, with data clustered at 1.0.
* **Rows (Model & Dataset):**
* Row 1: Llama-2-7B on WMT
* Row 2: Llama-2-7B on XSum
* Row 3: Llama-2-13B on WMT
* Row 4: Llama-2-13B on XSum
* Row 5: Llama-2-Chat-7B on WMT, XSum, and Dolly (3 sub-rows)
* Row 6: Llama-2-Chat-13B on WMT, XSum, and Dolly (3 sub-rows)
* **X-Axis:** "draft length" with ticks at 2, 3, 4, 5. Labels are only shown on the bottom row of charts.
* **Legend (Bottom Center):**
* `... SD` (dotted orange line)
* `--- SpecTr` (dashed red line)
* `--- RSD-C (ours)` (dashed green line with diamond markers)
* `— RSD-S (ours)` (solid blue line with circle markers)
### Detailed Analysis
**1. Block Efficiency (Column 1):**
* **Trend:** For nearly all model/dataset combinations, block efficiency increases as draft length increases from 2 to 5. The lines slope upward.
* **Performance Order:** RSD-S (blue solid) consistently achieves the highest block efficiency, followed closely by RSD-C (green dashed). SpecTr (red dashed) is generally lower, and SD (orange dotted) is the lowest.
* **Example Values (Approximate):** For Llama-2-7B/WMT at draft length 5: RSD-S ~2.8, RSD-C ~2.5, SpecTr ~2.2, SD ~1.8.
**2. MBSU (Column 2):**
* **Trend:** Similar upward trend with increasing draft length for most charts.
* **Performance Order:** RSD-S and RSD-C are again the top performers, with RSD-S often slightly higher. SpecTr and SD are lower.
* **Example Values (Approximate):** For Llama-2-13B/XSum at draft length 5: RSD-S ~3.9, RSD-C ~3.5, SpecTr ~3.1, SD ~2.7.
**3. Token Rate (Column 3):**
* **Trend:** Mixed trends. Some methods show a slight increase, others are flat or show a slight decrease with longer drafts. The Dolly dataset charts show more variability.
* **Performance Order:** RSD-S and RSD-C typically maintain the highest token rates. SD often shows a declining trend.
* **Notable Outlier:** In the Llama-2-Chat-7B/Dolly chart, the RSD-S (blue) line dips at draft length 5.
* **Example Values (Approximate):** For Llama-2-Chat-13B/WMT at draft length 4: RSD-S ~1.55, RSD-C ~1.45, SpecTr ~1.35, SD ~1.25.
**4. Accuracy (Column 4):**
* **Trend:** All four methods across all model/dataset combinations show a flat line at approximately 1.0 (perfect accuracy) for all draft lengths. There is no visible variation.
* **Performance Order:** All methods are indistinguishable, performing at the ceiling.
### Key Observations
1. **Consistent Superiority:** The proposed methods, RSD-S (blue) and RSD-C (green), consistently outperform the baselines (SpecTr and SD) across the block efficiency and MBSU metrics for all tested models and datasets.
2. **Accuracy Ceiling:** All methods achieve near-perfect accuracy (~1.0), indicating that the speculative decoding process does not introduce errors for these tasks and draft lengths.
3. **Metric Trade-offs:** While block efficiency and MBSU improve with draft length, the token rate does not show a universal improvement, suggesting a potential trade-off between efficiency per block and raw generation speed.
4. **Model/Chat Effect:** The trends are largely consistent between base models (Llama-2-7B/13B) and their chat-tuned versions (Llama-2-Chat-7B/13B), and across different datasets (WMT, XSum, Dolly).
### Interpretation
This grid of charts presents a comprehensive evaluation of a new speculative decoding technique (RSD, with variants C and S). The data strongly suggests that the RSD methods are more efficient (higher block efficiency and MBSU) than the compared baselines (SD and SpecDraft) without sacrificing accuracy. The consistent performance across diverse models (7B, 13B, base, chat) and tasks (translation, summarization, instruction following) indicates robustness.
The key finding is that RSD-S and RSD-C allow for more effective use of the draft mechanism, generating more valid tokens per speculative block (block efficiency) and achieving a higher overall utilization score (MBSU). The flat accuracy lines are crucial, confirming that these gains in efficiency do not come at the cost of output quality. The token rate data adds nuance, showing that simply increasing draft length doesn't always speed up generation linearly, but the efficiency gains of RSD are still evident. This work demonstrates a meaningful advancement in making large language model inference faster and more efficient.