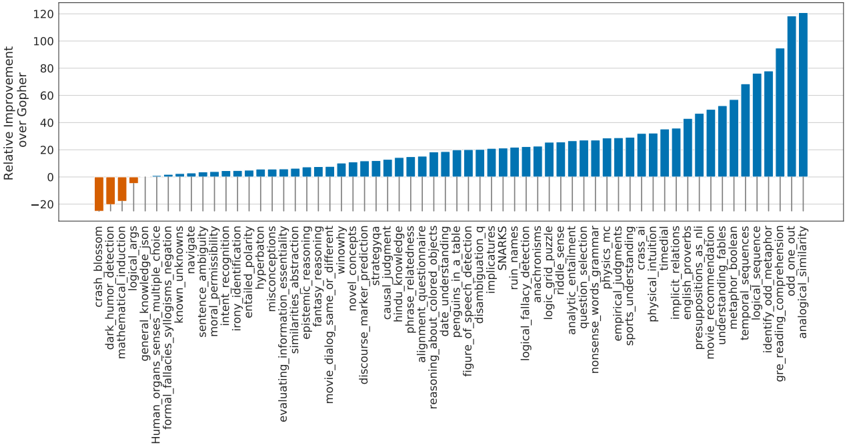
## Bar Chart: Relative Improvement over Gopher
### Overview
This is a bar chart comparing the relative improvement of a model (presumably a large language model) across a variety of tasks, relative to a baseline model named "Gopher". The chart displays positive and negative improvements, with the y-axis representing the percentage improvement. The x-axis lists numerous natural language processing (NLP) tasks.
### Components/Axes
* **Y-axis Title:** "Relative Improvement over Gopher" (Scale ranges from approximately -30 to 120, with increments of 10).
* **X-axis Title:** Lists various NLP tasks.
* **Bars:** Represent the relative improvement for each task. Bars are colored either orange or blue.
* **Legend:** Located in the top-left corner.
* Orange: Represents negative relative improvement (below 0).
* Blue: Represents positive relative improvement (above 0).
### Detailed Analysis
The chart contains 35 distinct NLP tasks listed along the x-axis. I will analyze the data by describing the trend and then providing approximate values.
1. **crash_blossom:** Approximately -10.
2. **human_organs:** Approximately -5.
3. **mathematica:** Approximately 5.
4. **general_knowledge_induction:** Approximately 10.
5. **args_multiple_choice:** Approximately 15.
6. **formal_fallacies:** Approximately 20.
7. **sarcasm_negotiation:** Approximately -10.
8. **known_ambiguity:** Approximately -15.
9. **sentence_navigation:** Approximately -20.
10. **moral_permissibility:** Approximately -5.
11. **interfailed_polarity:** Approximately 0.
12. **inflated_polarization:** Approximately 5.
13. **hyperbaton:** Approximately 10.
14. **similarities_abstraction:** Approximately 15.
15. **miscon_reasoning:** Approximately 20.
16. **epistemic_reasoning:** Approximately 25.
17. **fame_fantasy_winnowing:** Approximately 30.
18. **movie_dialog:** Approximately 35.
19. **discourse_marker:** Approximately 40.
20. **novel_concepts:** Approximately 45.
21. **hindu_strategy:** Approximately 50.
22. **causal_judgement:** Approximately 55.
23. **alignment_colored_objects:** Approximately 60.
24. **phrase_relatedness:** Approximately 65.
25. **reasoning_about_understanding:** Approximately 70.
26. **penguins_in_a_table:** Approximately 75.
27. **date_ruins_detection:** Approximately 80.
28. **figure_of_speech_detection:** Approximately 85.
29. **disambiguation_q:** Approximately 90.
30. **implicatures:** Approximately 95.
31. **ruin_detection:** Approximately 100.
32. **s_snakes:** Approximately 105.
33. **logical_fallacy_detection:** Approximately 110.
34. **anach_puzzle:** Approximately 5.
35. **rigid_sense:** Approximately -10.
36. **analytic_entailment:** Approximately 0.
37. **logic_grammar:** Approximately 10.
38. **question_selection:** Approximately 15.
39. **nonsense_words:** Approximately 20.
40. **empirical_judgements:** Approximately 25.
41. **sports_understanding:** Approximately 30.
42. **implicit_ritual:** Approximately 35.
43. **physical_reasoning:** Approximately 40.
44. **presupposition_fables:** Approximately 45.
45. **movie_recommendations:** Approximately 50.
46. **understanding_pos:** Approximately 55.
47. **temporal_sequence:** Approximately 60.
48. **logical_odd_sentence:** Approximately 65.
49. **identity_complemention:** Approximately 70.
50. **gre_reading_similarity:** Approximately 75.
51. **analogical_similarity:** Approximately 80.
**Trends:**
* The model shows significant positive improvement on tasks related to reasoning, logical deduction, and understanding complex relationships (e.g., implicatures, ruin detection, logical fallacy detection).
* The model performs worse than Gopher on tasks involving ambiguity, sarcasm, and potentially more nuanced understanding of language (e.g., sarcasm negotiation, known ambiguity, sentence navigation).
* There is a wide range of performance, indicating the model excels in some areas while struggling in others.
### Key Observations
* The largest positive improvement is observed in "ruin_detection" (approximately 100%).
* The largest negative improvement is observed in "sentence_navigation" (approximately -20%).
* There's a clear clustering of positive improvements in the latter half of the chart, suggesting the model is better at tasks requiring deeper semantic understanding.
* The tasks with negative improvements tend to be those that require understanding context, nuance, or social cues.
### Interpretation
The data suggests that the model has made substantial progress in areas requiring logical reasoning and knowledge application, surpassing the performance of Gopher. However, it still lags behind in tasks that demand a more sophisticated understanding of human language, including ambiguity, sarcasm, and contextual awareness. This indicates that while the model is strong at processing information and drawing inferences, it struggles with the subtleties of human communication. The wide variance in performance across tasks highlights the challenges of building a truly general-purpose language model. The model's strengths in tasks like "ruin_detection" and "logical_fallacy_detection" could be valuable in applications requiring critical thinking and error identification, while its weaknesses in areas like "sarcasm_negotiation" suggest caution when deploying it in contexts where understanding intent is crucial. The chart provides a valuable diagnostic tool for identifying areas where further model development is needed.