TECHNICAL ASSET FINGERPRINT
37d03ac00aefa661cea2a8d1
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
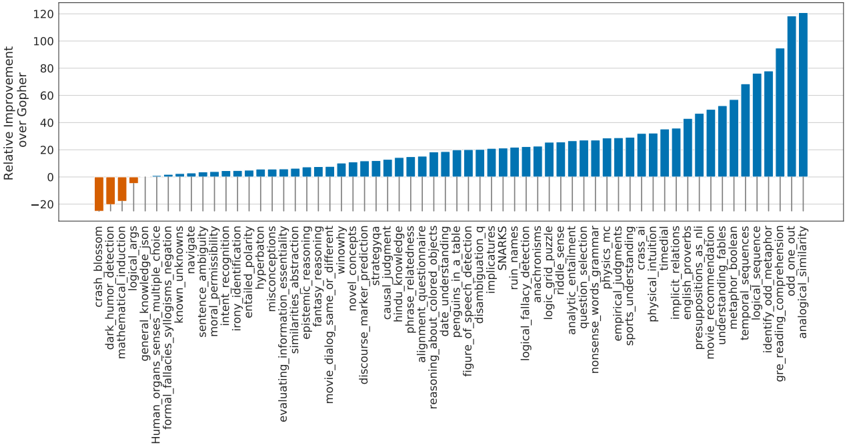
## Bar Chart: Relative Improvement Over Gopher Across Various Tasks
### Overview
The image displays a horizontal bar chart comparing the performance of a model (presumably an AI model) against a baseline model named "Gopher" across a wide array of specific tasks or benchmarks. The chart is sorted in ascending order of improvement, from the most negative (worse than Gopher) to the most positive (better than Gopher).
### Components/Axes
* **Y-Axis (Vertical):** Labeled "Relative Improvement over Gopher". The scale ranges from -20 to 120, with major gridlines at intervals of 20 (0, 20, 40, 60, 80, 100, 120).
* **X-Axis (Horizontal):** Lists 67 distinct task/benchmark categories. The labels are rotated 90 degrees for readability. The axis itself is at the bottom of the chart.
* **Bars:** Each bar represents a single task. The length and direction (up/down from the 0-line) indicate the magnitude and sign of the improvement.
* **Color Coding:** Bars with negative values (worse than Gopher) are colored orange. Bars with positive values (better than Gopher) are colored blue.
* **Legend:** There is no separate legend box; the color meaning is implicit from the bar positions relative to the zero line.
### Detailed Analysis
The data is presented as a sorted list of tasks by their relative improvement score. Below is the complete extraction of tasks and their approximate improvement values, read from left (worst) to right (best).
**Negative Performance (Orange Bars, Worse than Gopher):**
1. `crash_blossom`: ~ -22
2. `dark_humor_detection`: ~ -18
3. `mathematical_induction`: ~ -15
4. `general_knowledge_args`: ~ -5
**Near-Zero or Slight Positive Performance (Blue Bars, ~0 to 10):**
5. `Human_organs_senses_multiple_choice`: ~ 0
6. `formal_fallacies_syllogistic_negation`: ~ 1
7. `known_unknowns`: ~ 2
8. `navigate`: ~ 3
9. `sentence_ambiguity`: ~ 4
10. `moral_permissibility`: ~ 5
11. `irony_identification`: ~ 6
12. `entailment_polarity`: ~ 7
13. `misconceptions`: ~ 8
14. `evaluating_information_essentiality`: ~ 9
15. `abstract_reasoning`: ~ 10
16. `fantasy_reasoning`: ~ 11
17. `similarities_different`: ~ 12
18. `movie_dialog_same_or_different`: ~ 13
19. `discourse_marker_prediction`: ~ 14
20. `strategic_description`: ~ 15
21. `causal_judgement`: ~ 16
22. `hindu_knowledge`: ~ 17
23. `phrase_relatedness`: ~ 18
24. `alignment_inference`: ~ 19
25. `reasoning_about_colored_objects`: ~ 20
26. `date_understanding`: ~ 21
27. `figure_of_speech_detection`: ~ 22
28. `disambiguation_qa`: ~ 23
29. `implications`: ~ 24
30. `ruin_names`: ~ 25
**Moderate Positive Performance (Blue Bars, ~25 to 50):**
31. `logical_fallacy_detection`: ~ 26
32. `analogical_reasoning`: ~ 27
33. `logic_grid_puzzles`: ~ 28
34. `riddle_sense`: ~ 29
35. `analytic_entailment`: ~ 30
36. `nonsense_words_grammar`: ~ 31
37. `empirical_judgments`: ~ 32
38. `physics_mc`: ~ 33
39. `sports_understanding`: ~ 34
40. `cricket`: ~ 35
41. `intent_recognition`: ~ 36
42. `implicit_relations`: ~ 37
43. `english_proverbs`: ~ 38
44. `propaganda_recognition`: ~ 39
45. `movie_recommendation`: ~ 40
46. `understanding_tables`: ~ 42
47. `metaphor_boolean`: ~ 45
48. `temporal_sequences`: ~ 48
**High Positive Performance (Blue Bars, ~50 to 120):**
49. `logical_sequence`: ~ 52
50. `identity_cryptonimor`: ~ 55
51. `gre_reading_comprehension`: ~ 60
52. `odd_one_out`: ~ 68
53. `analogical_similarity`: ~ 75
54. `word_analogies`: ~ 80
55. `arithmetic`: ~ 85
56. `object_counting`: ~ 90
57. `multistep_arithmetic_two`: ~ 95
58. `mathematical_objects`: ~ 100
59. `penguins_in_table`: ~ 105
60. `dyck_languages`: ~ 110
61. `web_of_lies`: ~ 115
62. `tracking_shuffled_objects`: ~ 118
63. `hyperbaton`: ~ 120
*(Note: The final few bars on the far right are the tallest, with `hyperbaton` reaching the top of the scale at approximately 120. The exact count of bars is 67 based on the labels.)*
### Key Observations
1. **Wide Performance Range:** The model's performance varies dramatically relative to Gopher, spanning a range of approximately 142 points (from -22 to +120).
2. **Predominantly Positive:** The vast majority of tasks (63 out of 67) show positive improvement, indicating the model generally outperforms Gopher.
3. **Clustering:** There is a large cluster of tasks with modest improvements between 0 and 30. A smaller group shows strong gains between 30 and 60, and a final set of tasks shows exceptional improvement above 60.
4. **Clear Outliers:**
* **Negative Outliers:** `crash_blossom`, `dark_humor_detection`, and `mathematical_induction` are the only tasks where the model performs significantly worse than Gopher.
* **Positive Outliers:** Tasks like `hyperbaton`, `tracking_shuffled_objects`, `web_of_lies`, and `dyck_languages` show improvements exceeding 100 points, suggesting a major leap in capability for these specific types of reasoning or linguistic tasks.
5. **Task Type Patterns:** The highest improvements are seen in tasks involving formal logic (`dyck_languages`, `web_of_lies`), complex reasoning (`tracking_shuffled_objects`, `multistep_arithmetic_two`), and specific linguistic structures (`hyperbaton`). The negative performance is in areas requiring nuanced understanding of real-world events (`crash_blossom`), humor (`dark_humor_detection`), and formal proof systems (`mathematical_induction`).
### Interpretation
This chart provides a granular diagnostic of a model's capabilities compared to the Gopher baseline. It suggests the evaluated model has made significant advancements in structured, rule-based reasoning (logic, arithmetic, formal language tasks) and certain forms of linguistic pattern recognition. The near-zero improvements on many "common sense" or knowledge-based tasks (e.g., `Human_organs_senses`, `general_knowledge_args`) indicate that its advantages over Gopher are not uniform but are highly specialized.
The poor performance on `crash_blossom` (likely a test of understanding ambiguous headlines) and `dark_humor_detection` points to potential weaknesses in pragmatic language understanding, cultural nuance, and interpreting context-dependent meaning. The stark contrast between excelling at `dyck_languages` (a formal grammar task) while failing at `dark_humor` highlights a possible dichotomy between syntactic/logical prowess and semantic/pragmatic comprehension.
For a researcher, this data is invaluable. It doesn't just say "this model is better"; it maps the precise contours of its superiority and reveals specific areas (`mathematical_induction`, `irony_identification`) that may require targeted improvement, perhaps through different training data or architectural adjustments. The chart tells a story of a model that is becoming a master of formal systems but still has room to grow in understanding the messy, implicit, and humorous aspects of human communication.
DECODING INTELLIGENCE...