\n
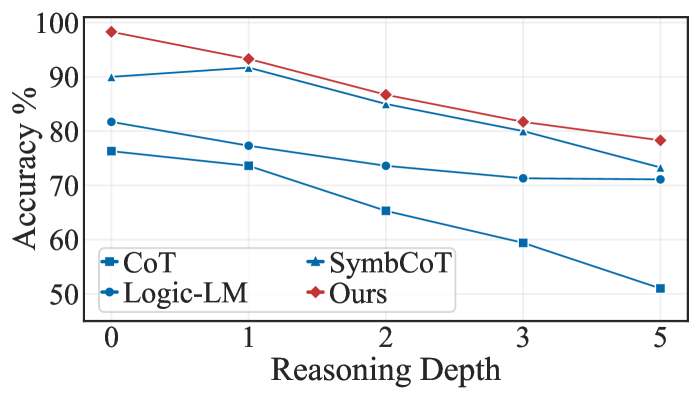
## Line Chart: Accuracy vs. Reasoning Depth
### Overview
This line chart depicts the relationship between Reasoning Depth and Accuracy (%) for four different models: CoT, Logic-LM, SymbCoT, and "Ours". The chart shows how the accuracy of each model changes as the reasoning depth increases from 0 to 5.
### Components/Axes
* **X-axis:** Reasoning Depth (ranging from 0 to 5).
* **Y-axis:** Accuracy (%) (ranging from 50% to 100%).
* **Legend:** Located in the bottom-center of the chart, identifying the four data series:
* CoT (Blue, Triangle Marker)
* Logic-LM (Dark Blue, Circle Marker)
* SymbCoT (Light Blue, Star Marker)
* Ours (Red, Diamond Marker)
* **Gridlines:** Horizontal and vertical gridlines are present to aid in reading values.
### Detailed Analysis
Here's a breakdown of each data series, with approximate values:
* **CoT (Blue, Triangle):** The line slopes downward consistently.
* Reasoning Depth 0: ~82%
* Reasoning Depth 1: ~78%
* Reasoning Depth 2: ~72%
* Reasoning Depth 3: ~68%
* Reasoning Depth 5: ~51%
* **Logic-LM (Dark Blue, Circle):** The line also slopes downward, but less steeply than CoT.
* Reasoning Depth 0: ~78%
* Reasoning Depth 1: ~75%
* Reasoning Depth 2: ~69%
* Reasoning Depth 3: ~65%
* Reasoning Depth 5: ~68%
* **SymbCoT (Light Blue, Star):** This line starts high and decreases, then flattens out.
* Reasoning Depth 0: ~92%
* Reasoning Depth 1: ~89%
* Reasoning Depth 2: ~65%
* Reasoning Depth 3: ~82%
* Reasoning Depth 5: ~75%
* **Ours (Red, Diamond):** This line starts at the highest accuracy and decreases, but remains relatively high throughout.
* Reasoning Depth 0: ~98%
* Reasoning Depth 1: ~94%
* Reasoning Depth 2: ~90%
* Reasoning Depth 3: ~85%
* Reasoning Depth 5: ~78%
### Key Observations
* "Ours" consistently outperforms the other models across all reasoning depths.
* CoT exhibits the most significant decrease in accuracy as reasoning depth increases.
* SymbCoT shows a notable drop in accuracy between reasoning depths 1 and 2.
* Logic-LM maintains a relatively stable accuracy compared to the other models.
### Interpretation
The data suggests that the "Ours" model is more robust to increased reasoning depth than the other models (CoT, Logic-LM, and SymbCoT). As the reasoning depth increases, the accuracy of CoT, Logic-LM, and SymbCoT declines, indicating a potential limitation in their ability to maintain performance with more complex reasoning chains. The initial high performance of SymbCoT is interesting, but its subsequent drop suggests it may be sensitive to specific types of reasoning challenges. The relatively stable performance of Logic-LM could indicate a different approach to reasoning that is less susceptible to depth-related issues. The consistent high accuracy of "Ours" suggests a more effective reasoning mechanism or a better ability to handle the complexities introduced by increased reasoning depth. The chart highlights the importance of considering reasoning depth when evaluating the performance of language models and suggests that "Ours" is a promising approach for tasks requiring deeper reasoning capabilities.