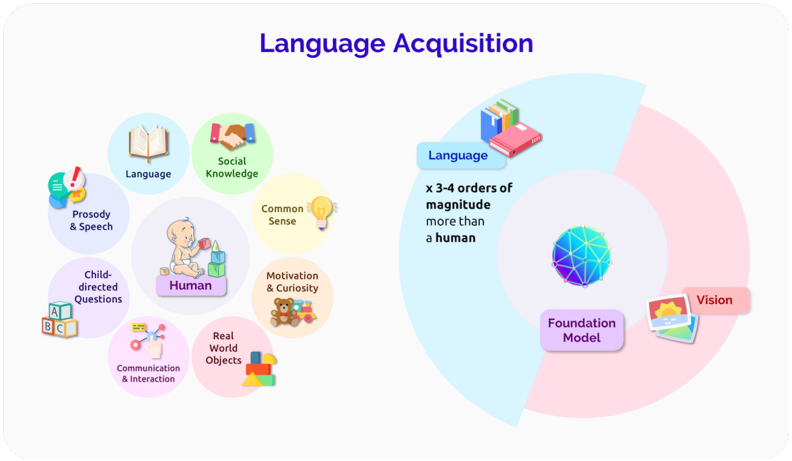
## Diagram: Language Acquisition
### Overview
The image is a comparative diagram illustrating the components of human language acquisition versus AI (Foundation Model) language capabilities. It features two primary sections:
1. **Left Side**: A central human figure surrounded by labeled circles representing factors contributing to human language learning.
2. **Right Side**: A pie chart comparing the "Language" capacity of humans versus AI, with a focus on magnitude differences.
### Components/Axes
#### Left Side (Human Language Acquisition Factors)
- **Central Human Figure**: Labeled "Human" with a child icon.
- **Surrounding Circles**:
- **Language**: Icon of an open book.
- **Social Knowledge**: Icon of two hands shaking.
- **Prosody & Speech**: Icon of a speech bubble with a star.
- **Child-directed Questions**: Icon of alphabet blocks (A, B, C).
- **Communication & Interaction**: Icon of a hand interacting with a speech bubble.
- **Common Sense**: Icon of a lightbulb.
- **Motivation & Curiosity**: Icon of a teddy bear with toys.
- **Real World Objects**: Icon of colorful building blocks.
#### Right Side (Pie Chart: Human vs. AI Language Capacity)
- **Title**: "Language x3-4 orders of magnitude more than a human" (blue section).
- **Sections**:
- **Blue (Language)**: Represents AI's language capacity, labeled with books and a red book.
- **Pink (Foundation Model)**: Labeled "Foundation Model" with a neural network icon and "Vision" with a sunset icon.
- **Legend**: Central circle with a neural network icon, linking "Foundation Model" to the pink section.
### Detailed Analysis
#### Left Side (Human Factors)
- **Labels**: All textual labels are explicitly stated (e.g., "Prosody & Speech," "Real World Objects").
- **Icons**: Each circle includes a distinct icon (e.g., alphabet blocks for "Child-directed Questions").
- **Spatial Arrangement**: Circles are evenly distributed around the human figure, emphasizing interconnectedness.
#### Right Side (Pie Chart)
- **Magnitude Comparison**: The blue "Language" section is visually larger than the pink "Foundation Model" section, with a textual note stating it is "x3-4 orders of magnitude more than a human."
- **Legend**: The central neural network icon connects the "Foundation Model" label to the pink section.
- **Vision Component**: The pink section includes a "Vision" label with a sunset icon, suggesting visual processing is part of the AI's architecture.
### Key Observations
1. **Human Language Acquisition**:
- Multifaceted, involving social, cognitive, and interactive elements (e.g., "Social Knowledge," "Communication & Interaction").
- No single factor dominates; all are interdependent.
2. **AI Language Capacity**:
- The "Language" section (blue) is significantly larger than the human's, emphasizing AI's scalability.
- The "Foundation Model" (pink) includes "Vision," indicating multimodal capabilities but lacks explicit social or interactive components.
3. **Contrast**:
- Human language is holistic and context-dependent, while AI's language is quantitatively larger but potentially less nuanced.
- The "Vision" component in AI suggests integration of visual data but does not replicate human social learning.
### Interpretation
The diagram highlights a critical distinction between human and AI language acquisition:
- **Humans** rely on a network of social, cognitive, and experiential factors, suggesting language is deeply embedded in lived experience.
- **AI** achieves superior language capacity through scale (3-4 orders of magnitude) but operates within a "Foundation Model" framework that prioritizes data-driven patterns over social or interactive learning.
- The inclusion of "Vision" in the AI model implies that visual data is leveraged, but this does not address the absence of human-like social or motivational drivers.
This contrast underscores the limitations of current AI in replicating the richness of human language, which is shaped by dynamic, context-rich interactions rather than static data processing.