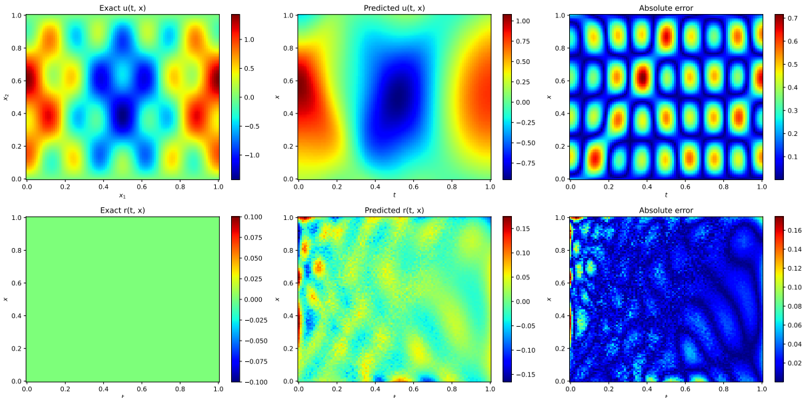
## Heatmap Comparison: Exact vs. Predicted Solutions and Absolute Error
### Overview
The image presents a comparison between exact and predicted solutions for two functions, u(t, x) and r(t, x), along with their absolute errors. The data is visualized using heatmaps, where color intensity represents the function's value at different points. The x and y axes represent spatial or temporal dimensions.
### Components/Axes
**Top Row:**
* **Left:** "Exact u(t, x)" - Heatmap of the exact solution for function u(t, x).
* X-axis: x1, ranging from 0.0 to 1.0
* Y-axis: x2, ranging from 0.0 to 1.0
* Color scale: Ranges from approximately -1.0 (dark blue) to 1.0 (red).
* **Center:** "Predicted u(t, x)" - Heatmap of the predicted solution for function u(t, x).
* X-axis: t, ranging from 0.0 to 1.0
* Y-axis: x, ranging from 0.0 to 1.0
* Color scale: Ranges from approximately -0.75 (dark blue) to 1.0 (red).
* **Right:** "Absolute error" - Heatmap of the absolute error between the exact and predicted solutions for u(t, x).
* X-axis: t, ranging from 0.0 to 1.0
* Y-axis: x, ranging from 0.0 to 1.0
* Color scale: Ranges from approximately 0.0 (dark blue) to 0.7 (red).
**Bottom Row:**
* **Left:** "Exact r(t, x)" - Heatmap of the exact solution for function r(t, x).
* X-axis: t, ranging from 0.0 to 1.0
* Y-axis: x, ranging from 0.0 to 1.0
* Color scale: Ranges from approximately -0.1 (dark blue) to 0.1 (red). The entire plot is predominantly green, indicating values close to 0.
* **Center:** "Predicted r(t, x)" - Heatmap of the predicted solution for function r(t, x).
* X-axis: t, ranging from 0.0 to 1.0
* Y-axis: x, ranging from 0.0 to 1.0
* Color scale: Ranges from approximately -0.15 (dark blue) to 0.15 (red).
* **Right:** "Absolute error" - Heatmap of the absolute error between the exact and predicted solutions for r(t, x).
* X-axis: t, ranging from 0.0 to 1.0
* Y-axis: x, ranging from 0.0 to 1.0
* Color scale: Ranges from approximately 0.0 (dark blue) to 0.16 (red).
### Detailed Analysis
**Exact u(t, x):**
The heatmap shows a complex pattern with alternating regions of high (red) and low (blue) values. There are several distinct "blobs" of high and low values distributed across the space.
**Predicted u(t, x):**
The predicted solution shows a smoother pattern compared to the exact solution. There's a large blue region in the center, flanked by red regions on the sides.
**Absolute error (u(t, x)):**
The absolute error heatmap shows a repeating pattern of high and low error regions. The error appears to be higher in areas where the exact solution has sharp transitions.
**Exact r(t, x):**
The exact solution for r(t, x) is almost uniformly green, indicating a value close to zero across the entire domain.
**Predicted r(t, x):**
The predicted solution for r(t, x) shows more variation than the exact solution, with a mix of blue, green, and yellow regions.
**Absolute error (r(t, x)):**
The absolute error for r(t, x) is generally low, but there are some regions of higher error, particularly near the boundaries.
### Key Observations
* The predicted solution for u(t, x) captures the general shape of the exact solution but misses some of the finer details.
* The absolute error for u(t, x) is significant in some regions, indicating that the prediction is not perfect.
* The exact solution for r(t, x) is close to zero, while the predicted solution shows some deviation.
* The absolute error for r(t, x) is generally low, but there are some areas where the error is higher.
### Interpretation
The heatmaps provide a visual comparison of the exact and predicted solutions for two functions, u(t, x) and r(t, x). The absolute error heatmaps highlight the regions where the predictions deviate most from the exact solutions. The results suggest that the prediction model performs reasonably well for u(t, x), capturing the overall pattern but missing some details. For r(t, x), the exact solution is close to zero, and the prediction introduces some noise, resulting in a small but non-zero error. The higher error near the boundaries in the "Absolute error (r(t, x))" plot might indicate boundary condition issues in the prediction model.