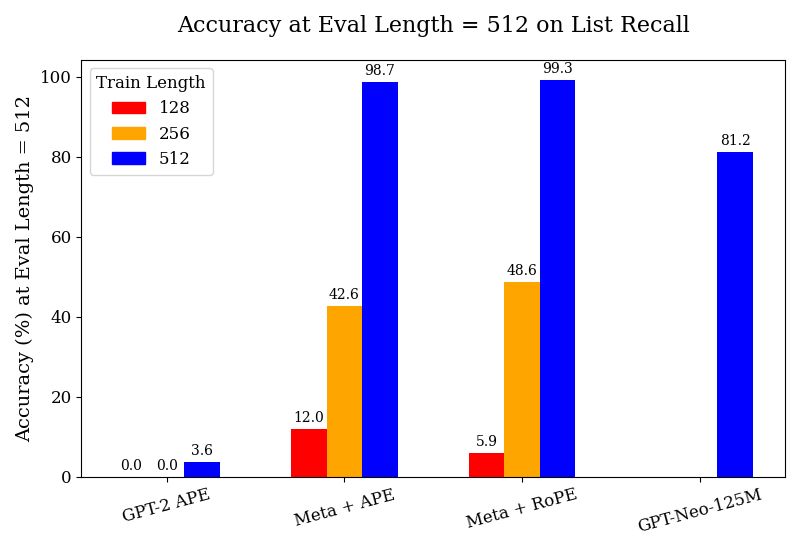
## Bar Chart: Accuracy at Eval Length = 512 on List Recall
### Overview
The chart compares the accuracy of four language models (GPT-2 APE, Meta + APE, Meta + RoPE, GPT-Neo-125M) at an evaluation length of 512 tokens, measured on list recall. Accuracy is shown for three training lengths (128, 256, 512 tokens), with distinct colors for each training length. The y-axis represents accuracy percentage, while the x-axis lists the models.
### Components/Axes
- **X-axis (Models)**:
- GPT-2 APE
- Meta + APE
- Meta + RoPE
- GPT-Neo-125M
- **Y-axis (Accuracy %)**: Ranges from 0 to 100.
- **Legend (Top-left)**:
- Red: Train Length = 128
- Orange: Train Length = 256
- Blue: Train Length = 512
### Detailed Analysis
1. **GPT-2 APE**:
- Train Length = 128: 0.0% (red bar absent).
- Train Length = 256: 0.0% (orange bar absent).
- Train Length = 512: 3.6% (blue bar).
2. **Meta + APE**:
- Train Length = 128: 12.0% (red bar).
- Train Length = 256: 42.6% (orange bar).
- Train Length = 512: 98.7% (blue bar).
3. **Meta + RoPE**:
- Train Length = 128: 5.9% (red bar).
- Train Length = 256: 48.6% (orange bar).
- Train Length = 512: 99.3% (blue bar).
4. **GPT-Neo-125M**:
- Train Length = 128: 0.0% (red bar absent).
- Train Length = 256: 0.0% (orange bar absent).
- Train Length = 512: 81.2% (blue bar).
### Key Observations
- **Trend Verification**:
- For **Meta + APE** and **Meta + RoPE**, accuracy increases sharply with longer training lengths (e.g., 12.0% → 42.6% → 98.7% for Meta + APE).
- **GPT-2 APE** and **GPT-Neo-125M** show no improvement at shorter training lengths (128/256), with GPT-2 APE performing poorly even at 512 tokens (3.6%).
- **Meta + RoPE** achieves the highest accuracy (99.3%) at 512 tokens, slightly outperforming **Meta + APE** (98.7%).
- **Notable Outliers**:
- **GPT-2 APE** underperforms across all training lengths, suggesting architectural limitations.
- **GPT-Neo-125M** achieves moderate accuracy (81.2%) at 512 tokens but lacks data for shorter lengths, leaving its scalability unclear.
### Interpretation
The data demonstrates that:
1. **Training Length Matters**: Longer training (512 tokens) significantly improves accuracy for **Meta + APE** (+86.7% increase from 128 to 512 tokens) and **Meta + RoPE** (+93.4% increase).
2. **Model Architecture Dominates**: **Meta + RoPE** outperforms **Meta + APE** despite similar training lengths, indicating RoPE may enhance recall efficiency.
3. **Scalability Limits**: **GPT-2 APE** and **GPT-Neo-125M** show minimal or no improvement at shorter lengths, suggesting they require longer training to achieve meaningful performance gains.
4. **Efficiency Trade-offs**: **Meta + RoPE** achieves near-perfect accuracy (99.3%) with 512 tokens, implying it balances model size and training efficiency better than alternatives.
This chart highlights the importance of training duration and architectural choices (e.g., RoPE vs. APE) in optimizing list recall accuracy for language models.