## Bar Chart: Accuracy at Eval Length = 512 on List Recall
### Overview
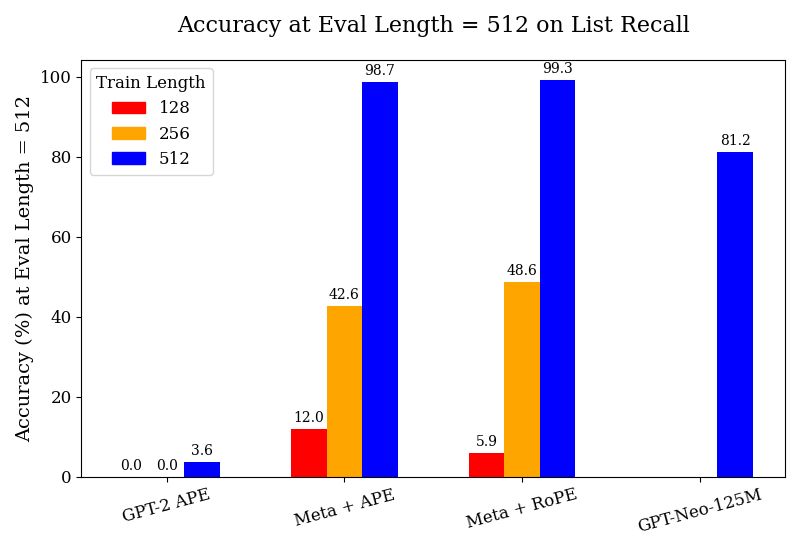
This bar chart displays the accuracy (%) at an evaluation length of 512 on list recall for different models (GPT-2 APE, Meta + APE, Meta + RoPE, and GPT-Neo-125M) and varying train lengths (128, 256, and 512). The chart uses a grouped bar format to compare the performance of each model across different training lengths.
### Components/Axes
* **Title:** Accuracy at Eval Length = 512 on List Recall
* **X-axis:** Model Name (GPT-2 APE, Meta + APE, Meta + RoPE, GPT-Neo-125M)
* **Y-axis:** Accuracy (%) at Eval Length = 512
* **Legend:**
* Train Length: 128 (Red)
* Train Length: 256 (Orange)
* Train Length: 512 (Blue)
### Detailed Analysis
The chart consists of four groups of three bars, one for each model and train length combination.
* **GPT-2 APE:**
* Train Length 128: Accuracy ≈ 0.0%
* Train Length 256: Accuracy ≈ 3.6%
* Train Length 512: Accuracy ≈ 0.0%
* **Meta + APE:**
* Train Length 128: Accuracy ≈ 12.0%
* Train Length 256: Accuracy ≈ 42.6%
* Train Length 512: Accuracy ≈ 98.7%
* **Meta + RoPE:**
* Train Length 128: Accuracy ≈ 5.9%
* Train Length 256: Accuracy ≈ 48.6%
* Train Length 512: Accuracy ≈ 99.3%
* **GPT-Neo-125M:**
* Train Length 128: Not present
* Train Length 256: Not present
* Train Length 512: Accuracy ≈ 81.2%
The bars for each model generally increase in height as the train length increases, indicating a positive correlation between train length and accuracy.
### Key Observations
* GPT-2 APE consistently shows very low accuracy across all train lengths, with the highest accuracy at 3.6% for a train length of 256.
* Meta + APE and Meta + RoPE demonstrate a significant improvement in accuracy as the train length increases, reaching very high accuracy levels (98.7% and 99.3% respectively) with a train length of 512.
* GPT-Neo-125M shows a reasonable accuracy of approximately 81.2% with a train length of 512, but it is lower than the accuracy achieved by Meta + APE and Meta + RoPE.
* The largest performance gains are observed when increasing the train length from 256 to 512 for Meta + APE and Meta + RoPE.
### Interpretation
The data suggests that increasing the train length significantly improves the accuracy of the models, particularly for Meta + APE and Meta + RoPE. These models appear to benefit substantially from larger training datasets. GPT-2 APE consistently underperforms compared to the other models, indicating that its architecture or training process may be less effective for this task. GPT-Neo-125M provides a moderate level of accuracy, falling between GPT-2 APE and the Meta models. The difference in performance between Meta + APE and Meta + RoPE is minimal, suggesting that the RoPE mechanism does not provide a substantial advantage in this specific scenario. The chart highlights the importance of train length in achieving high accuracy on list recall tasks, and it suggests that Meta + APE and Meta + RoPE are promising architectures for this type of problem. The lack of data for GPT-Neo-125M at train lengths 128 and 256 could indicate that it was not trained with those parameters, or that the results were not significant enough to be included.