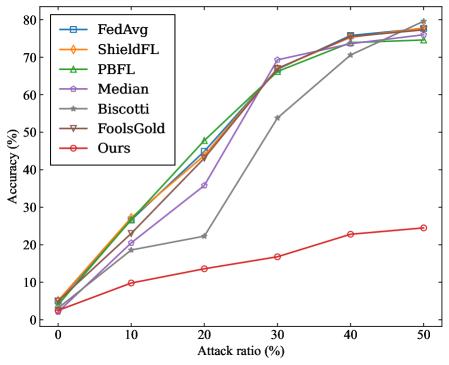
\n
## Line Chart: Accuracy vs. Attack Ratio for Federated Learning Defense Mechanisms
### Overview
This line chart depicts the accuracy of several Federated Learning (FL) defense mechanisms against varying attack ratios. The x-axis represents the attack ratio (in percentage), and the y-axis represents the accuracy (also in percentage). Six different defense mechanisms are compared: FedAvg, ShieldFL, PBFL, Median, Biscotti, FoolsGold, and "Ours" (presumably a novel method).
### Components/Axes
* **X-axis:** "Attack ratio (%)" - Scale ranges from 0% to 50%, with markers at 0, 10, 20, 30, 40, and 50.
* **Y-axis:** "Accuracy (%)" - Scale ranges from 0% to 80%, with markers at 0, 10, 20, 30, 40, 50, 60, 70, and 80.
* **Legend:** Located in the top-left corner, listing the following defense mechanisms with corresponding line colors:
* FedAvg (Blue)
* ShieldFL (Orange)
* PBFL (Green)
* Median (Purple)
* Biscotti (Grey)
* FoolsGold (Brown)
* Ours (Red)
### Detailed Analysis
Here's a breakdown of each line's trend and approximate data points, verified against the legend colors:
* **FedAvg (Blue):** The line starts at approximately 0% accuracy at 0% attack ratio. It increases steadily, reaching approximately 74% accuracy at 50% attack ratio.
* **ShieldFL (Orange):** Starts at 0% accuracy at 0% attack ratio. It rises sharply, reaching approximately 75% accuracy at 50% attack ratio.
* **PBFL (Green):** Starts at 0% accuracy at 0% attack ratio. It increases rapidly, reaching approximately 72% accuracy at 50% attack ratio.
* **Median (Purple):** Starts at 0% accuracy at 0% attack ratio. It increases steadily, reaching approximately 72% accuracy at 50% attack ratio.
* **Biscotti (Grey):** Starts at 0% accuracy at 0% attack ratio. It increases slowly, reaching approximately 30% accuracy at 50% attack ratio.
* **FoolsGold (Brown):** Starts at 0% accuracy at 0% attack ratio. It increases slowly, reaching approximately 25% accuracy at 50% attack ratio.
* **Ours (Red):** Starts at 0% accuracy at 0% attack ratio. It increases slowly and consistently, reaching approximately 24% accuracy at 50% attack ratio.
Approximate data points (Attack Ratio, Accuracy):
* **0% Attack Ratio:** All methods are at approximately 0% accuracy.
* **10% Attack Ratio:** FedAvg ~ 20%, ShieldFL ~ 25%, PBFL ~ 25%, Median ~ 25%, Biscotti ~ 10%, FoolsGold ~ 10%, Ours ~ 10%.
* **20% Attack Ratio:** FedAvg ~ 45%, ShieldFL ~ 50%, PBFL ~ 45%, Median ~ 45%, Biscotti ~ 20%, FoolsGold ~ 15%, Ours ~ 15%.
* **30% Attack Ratio:** FedAvg ~ 60%, ShieldFL ~ 65%, PBFL ~ 60%, Median ~ 60%, Biscotti ~ 25%, FoolsGold ~ 20%, Ours ~ 18%.
* **40% Attack Ratio:** FedAvg ~ 70%, ShieldFL ~ 72%, PBFL ~ 68%, Median ~ 68%, Biscotti ~ 28%, FoolsGold ~ 22%, Ours ~ 22%.
* **50% Attack Ratio:** FedAvg ~ 74%, ShieldFL ~ 75%, PBFL ~ 72%, Median ~ 72%, Biscotti ~ 30%, FoolsGold ~ 25%, Ours ~ 24%.
### Key Observations
* FedAvg, ShieldFL, PBFL, and Median consistently exhibit significantly higher accuracy compared to Biscotti, FoolsGold, and "Ours" across all attack ratios.
* ShieldFL appears to perform slightly better than other methods at higher attack ratios (40% and 50%).
* Biscotti, FoolsGold, and "Ours" show very limited improvement in accuracy as the attack ratio increases.
* The performance gap between the top-performing methods (FedAvg, ShieldFL, PBFL, Median) and the lower-performing ones (Biscotti, FoolsGold, "Ours") widens as the attack ratio increases.
### Interpretation
The data suggests that the defense mechanisms represented by FedAvg, ShieldFL, PBFL, and Median are substantially more effective at mitigating the impact of attacks on Federated Learning models than Biscotti, FoolsGold, and the proposed "Ours" method. The consistent high accuracy of the former group indicates their robustness against increasing attack ratios.
The relatively flat lines for Biscotti, FoolsGold, and "Ours" suggest that these methods either offer minimal protection or are easily circumvented by the attacks being simulated. The fact that their accuracy barely improves with increasing attack ratio implies they do not scale well in defending against more aggressive attacks.
The slight edge of ShieldFL at higher attack ratios could indicate a specific advantage in handling more sophisticated attack strategies. The overall trend highlights the importance of selecting robust defense mechanisms in Federated Learning environments to maintain model accuracy and reliability in the face of adversarial threats. The "Ours" method, while potentially novel, appears to underperform compared to established techniques. Further investigation into its design and implementation is warranted to understand its limitations.