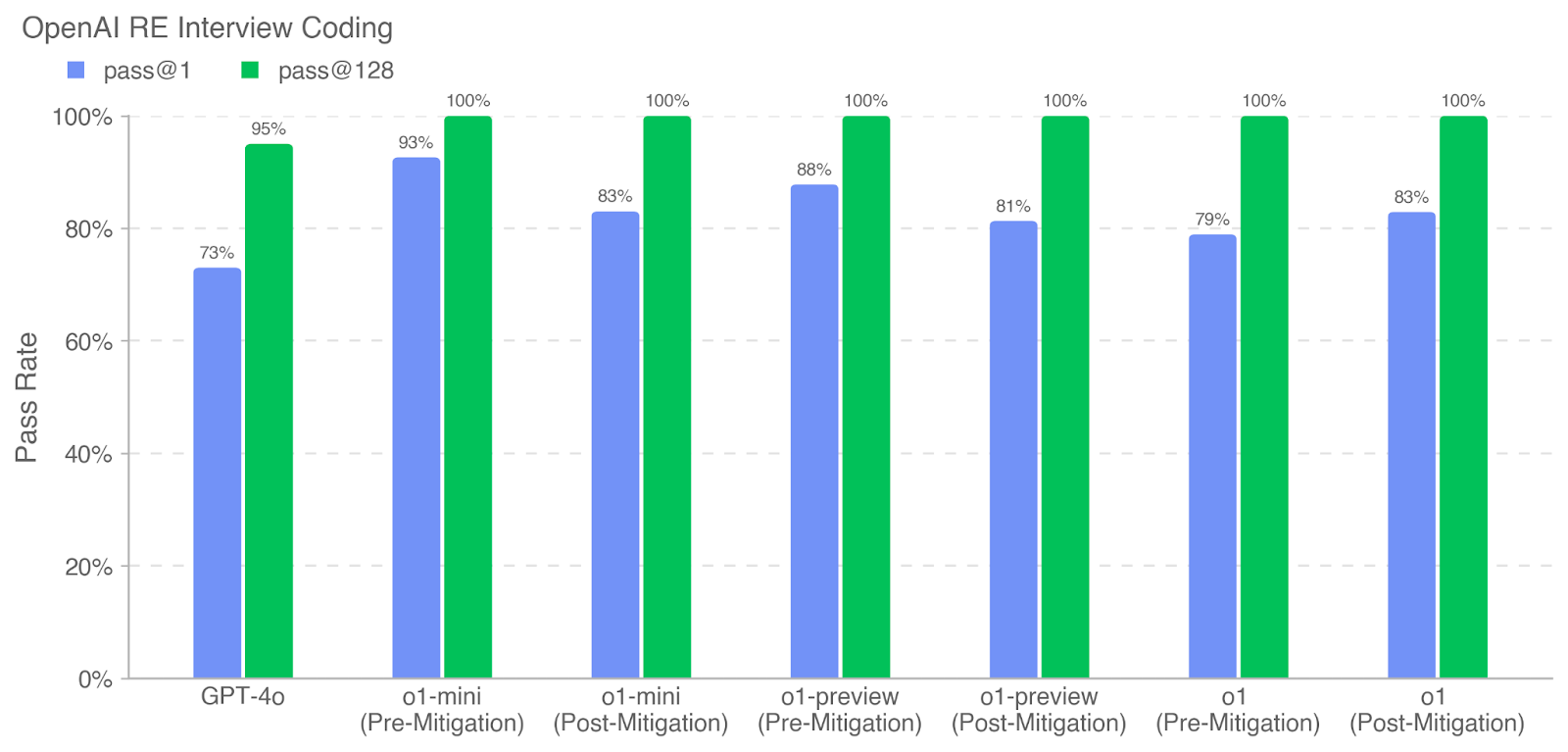
## Bar Chart: OpenAI RE Interview Coding Pass Rates
### Overview
This bar chart displays the pass rates for OpenAI RE (Research Engineer) interview coding assessments, comparing two metrics: `pass@1` and `pass@128`, across different model versions. The chart shows the pass rate on the Y-axis (from 0% to 100%) and the model version on the X-axis. Each model version has two bars representing the two pass rate metrics, pre- and post-mitigation.
### Components/Axes
* **Title:** OpenAI RE Interview Coding
* **Y-axis Label:** Pass Rate
* **X-axis Labels (Categories):** GPT-4o, o1-mini (Pre-Mitigation), o1-mini (Post-Mitigation), o1-preview (Pre-Mitigation), o1-preview (Post-Mitigation), o1 (Pre-Mitigation), o1 (Post-Mitigation)
* **Legend:**
* `pass@1` (Blue)
* `pass@128` (Green)
* **Y-axis Scale:** Linear, from 0% to 100%, with increments of 20%.
### Detailed Analysis
The chart consists of paired bars for each model version, representing `pass@1` and `pass@128`.
* **GPT-4o:**
* `pass@1`: Approximately 73%
* `pass@128`: Approximately 95%
* **o1-mini (Pre-Mitigation):**
* `pass@1`: Approximately 93%
* `pass@128`: Approximately 100%
* **o1-mini (Post-Mitigation):**
* `pass@1`: Approximately 83%
* `pass@128`: Approximately 100%
* **o1-preview (Pre-Mitigation):**
* `pass@1`: Approximately 88%
* `pass@128`: Approximately 100%
* **o1-preview (Post-Mitigation):**
* `pass@1`: Approximately 81%
* `pass@128`: Approximately 100%
* **o1 (Pre-Mitigation):**
* `pass@1`: Approximately 79%
* `pass@128`: Approximately 100%
* **o1 (Post-Mitigation):**
* `pass@1`: Approximately 83%
* `pass@128`: Approximately 100%
The `pass@128` metric consistently shows a 100% pass rate for all models, both pre- and post-mitigation. The `pass@1` metric varies more significantly across models.
### Key Observations
* `pass@128` is consistently 100% across all models and conditions.
* GPT-4o has the lowest `pass@1` rate at approximately 73%.
* Mitigation appears to sometimes *decrease* the `pass@1` rate (e.g., o1-mini), while other times it increases it (e.g., o1).
* The `pass@1` rate is generally higher for the "mini" and "preview" models compared to GPT-4o and the base "o1" model.
### Interpretation
The data suggests that the models perform very well on the coding assessment when evaluated with 128 test cases (`pass@128`). This could indicate that the models are robust and can handle a large number of diverse coding challenges. However, performance is more variable when evaluated with only one test case (`pass@1`), suggesting that the models may be more sensitive to the specific characteristics of that single test case.
The varying impact of mitigation on `pass@1` is interesting. It suggests that the mitigation strategies may be beneficial in some cases but detrimental in others. This could be due to the specific nature of the mitigation and the characteristics of the model being mitigated. The lower `pass@1` rate for GPT-4o could indicate that this model requires more targeted mitigation strategies to improve its performance on single-case coding assessments.
The consistent 100% `pass@128` rate across all models suggests that the assessment is well-designed and can effectively differentiate between models based on their overall coding capabilities. The differences in `pass@1` rates provide additional insights into the strengths and weaknesses of each model.