## Bar Chart: OpenAI RE Interview Coding Pass Rates
### Overview
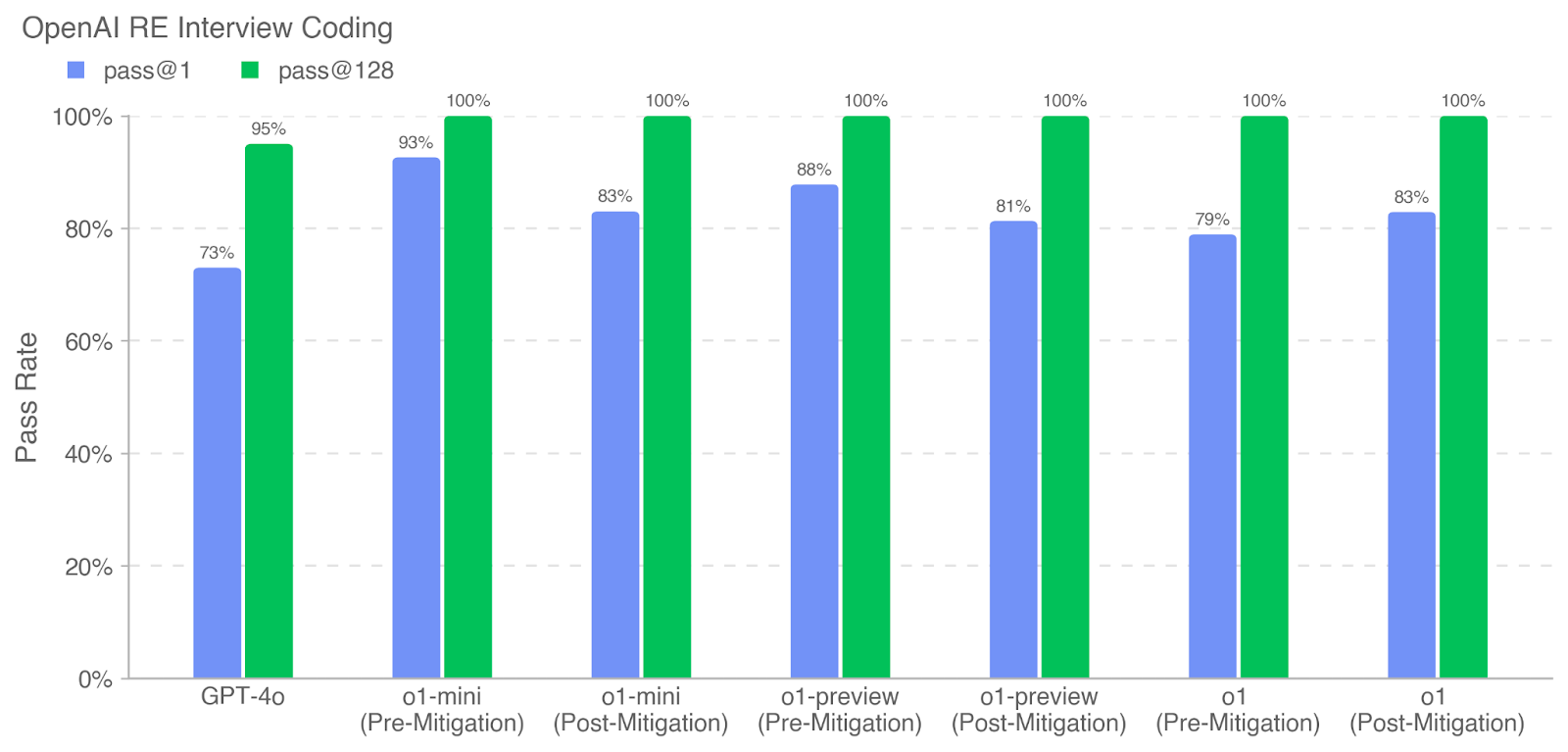
The chart compares pass rates for two evaluation thresholds ("pass@1" and "pass@128") across different AI models and mitigation scenarios. All "pass@128" bars reach 100%, while "pass@1" rates vary significantly between models and mitigation states.
### Components/Axes
- **X-Axis**: Model variants and mitigation status
- Categories:
1. GPT-4o
2. o1-mini (Pre-Mitigation)
3. o1-mini (Post-Mitigation)
4. o1-preview (Pre-Mitigation)
5. o1-preview (Post-Mitigation)
6. o1 (Pre-Mitigation)
7. o1 (Post-Mitigation)
- **Y-Axis**: Pass Rate (0% to 100%)
- **Legend**:
- Blue = pass@1
- Green = pass@128
- **Placement**: Legend in top-left, bars grouped by category with dual bars per category
### Detailed Analysis
1. **GPT-4o**:
- pass@1: 73% (blue)
- pass@128: 95% (green)
2. **o1-mini**:
- Pre-Mitigation: pass@1 = 93%, pass@128 = 100%
- Post-Mitigation: pass@1 = 83%, pass@128 = 100%
3. **o1-preview**:
- Pre-Mitigation: pass@1 = 88%, pass@128 = 100%
- Post-Mitigation: pass@1 = 81%, pass@128 = 100%
4. **o1**:
- Pre-Mitigation: pass@1 = 79%, pass@128 = 100%
- Post-Mitigation: pass@1 = 83%, pass@128 = 100%
### Key Observations
1. **Universal pass@128 Success**: All models achieve 100% pass@128, indicating robust performance at this threshold regardless of mitigation.
2. **pass@1 Variability**:
- GPT-4o has the lowest pass@1 (73%)
- o1-mini shows the highest pre-mitigation pass@1 (93%) but drops to 83% post-mitigation
- o1-preview and o1 models show mixed mitigation effects (o1-preview: -7%, o1: +4%)
3. **Mitigation Impact**:
- o1-mini and o1-preview show performance degradation post-mitigation
- o1 shows improvement post-mitigation
4. **Threshold Sensitivity**: pass@1 rates are 15-25% lower than pass@128 across all models, highlighting stricter evaluation at the 1% threshold.
### Interpretation
The data demonstrates that while all models achieve perfect performance at the 128-sample threshold, their performance at the stricter 1-sample threshold varies significantly. The mitigation process appears to have inconsistent effects:
- **o1-mini** and **o1-preview** show performance degradation post-mitigation, suggesting potential over-optimization or unintended consequences
- **o1** shows improvement post-mitigation, indicating successful alignment adjustments
- GPT-4o's lower pass@1 rate (73%) despite high pass@128 suggests fundamental architectural differences in handling single-sample evaluations
The consistent 100% pass@128 across all models implies that the evaluation framework's 128-sample threshold may be more aligned with the models' training objectives, while the 1-sample threshold exposes model-specific weaknesses. The mixed mitigation results highlight the complexity of balancing performance and safety objectives in AI development.