TECHNICAL ASSET FINGERPRINT
39756d787246409785e79ae2
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
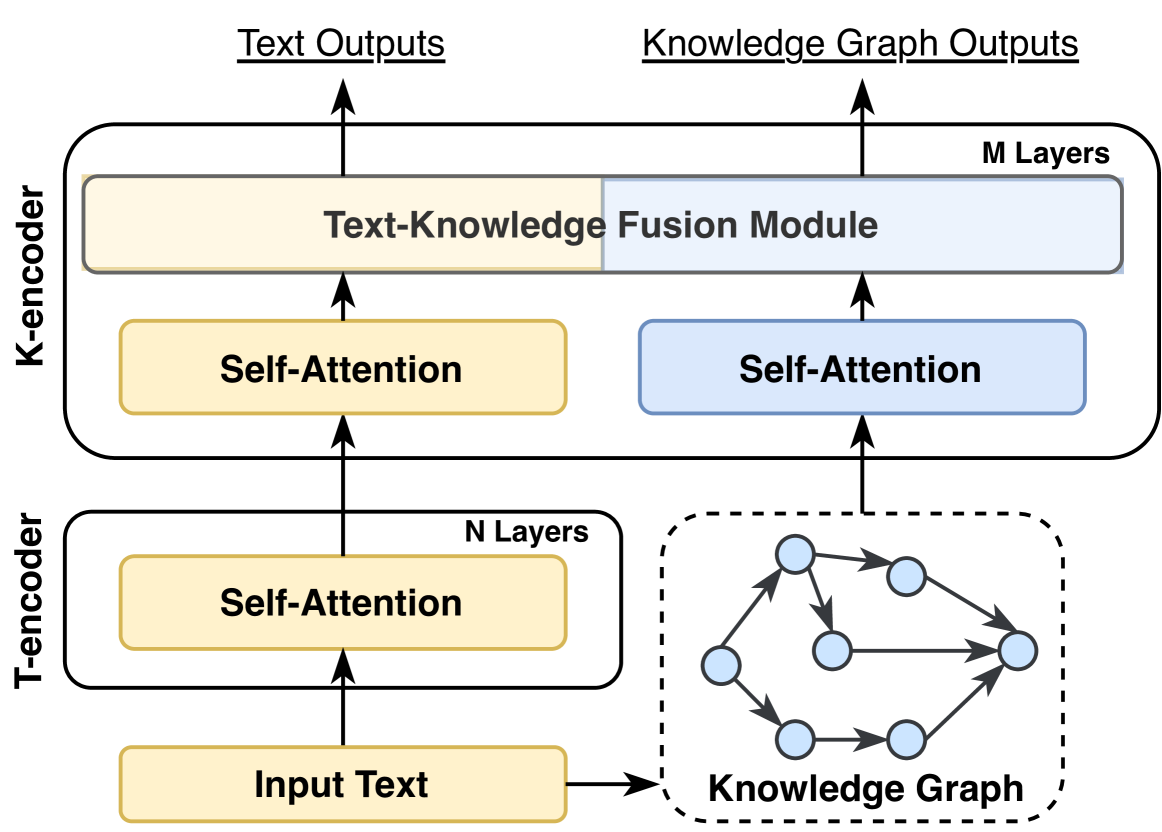
## [Diagram]: Neural Network Architecture for Text and Knowledge Graph Fusion
### Overview
The image displays a technical diagram of a neural network architecture designed to process both textual input and structured knowledge from a knowledge graph. The architecture consists of two primary encoder modules: a **T-encoder** (Text encoder) and a **K-encoder** (Knowledge encoder), which work in parallel before their outputs are fused. The system produces two distinct outputs: **Text Outputs** and **Knowledge Graph Outputs**.
### Components/Axes
The diagram is organized vertically, with data flowing from the bottom (input) to the top (outputs).
**1. Input Layer (Bottom):**
* **Input Text:** A yellow rectangular box at the bottom-left labeled "Input Text". This is the starting point for the textual data stream.
* **Knowledge Graph:** A dashed-line box at the bottom-right containing a graphical representation of a knowledge graph. It consists of seven light-blue circular nodes connected by directed black arrows, indicating relationships. The label "Knowledge Graph" is below this graphic.
**2. T-encoder (Lower Module):**
* A rounded rectangular container labeled "T-encoder" on its left side.
* Contains a sub-label "N Layers" in its top-right corner.
* Inside, a single yellow rectangular box labeled "Self-Attention".
* **Data Flow:** An arrow points upward from "Input Text" into the "Self-Attention" box. Another arrow points upward from the "Self-Attention" box to the K-encoder above.
**3. K-encoder (Upper Module):**
* A larger rounded rectangular container labeled "K-encoder" on its left side.
* Contains a sub-label "M Layers" in its top-right corner.
* **Internal Components:**
* **Left (Text Path):** A yellow rectangular box labeled "Self-Attention". An arrow from the T-encoder's output points into this box.
* **Right (Knowledge Path):** A light-blue rectangular box labeled "Self-Attention". An arrow from the "Knowledge Graph" points into this box.
* **Fusion Module:** A large horizontal rectangle spanning the top of the K-encoder, divided into two colored sections. The left (yellow) section is labeled "Text-Knowledge Fusion Module". The right (light-blue) section is unlabeled but is part of the same module. Arrows from both the left and right "Self-Attention" boxes point upward into this fusion module.
**4. Output Layer (Top):**
* **Text Outputs:** A label at the top-left with an arrow pointing upward from the yellow section of the "Text-Knowledge Fusion Module".
* **Knowledge Graph Outputs:** A label at the top-right with an arrow pointing upward from the blue section of the "Text-Knowledge Fusion Module".
### Detailed Analysis
**Component Isolation & Flow:**
* **Region 1 (Input):** The system takes two parallel inputs: raw text and a structured knowledge graph.
* **Region 2 (T-encoder):** The text undergoes initial processing through `N` layers of self-attention mechanisms, which contextualize the textual tokens.
* **Region 3 (K-encoder):** This is the core fusion engine.
* The pre-processed text from the T-encoder enters a dedicated self-attention layer (yellow).
* Simultaneously, the knowledge graph data enters its own separate self-attention layer (blue), likely to encode the graph structure and node features.
* The outputs from these two parallel self-attention streams are fed into the **Text-Knowledge Fusion Module**. This module is the critical junction where information from the text and the knowledge graph is integrated.
* **Region 4 (Output):** The fused representation is then split to generate two specialized outputs: one optimized for text-based tasks and another for knowledge graph-based tasks.
**Spatial Grounding:**
* The **T-encoder** is positioned in the lower-left quadrant.
* The **Knowledge Graph** diagram is in the lower-right quadrant.
* The **K-encoder** occupies the upper half of the image, centered.
* The **Text-Knowledge Fusion Module** is the topmost internal component of the K-encoder, spanning its full width.
* The **Output labels** are positioned at the very top, aligned with their respective data paths (Text on left, Knowledge Graph on right).
### Key Observations
1. **Dual-Stream Architecture:** The design explicitly maintains separate processing pathways for text and knowledge graph data until the fusion stage, suggesting a need to preserve their distinct structural properties.
2. **Asymmetric Depth:** The T-encoder uses `N` layers, while the K-encoder uses `M` layers. This implies the knowledge fusion and encoding process may require a different (potentially deeper or shallower) level of processing complexity than initial text encoding.
3. **Fusion Before Final Output:** Integration happens within the K-encoder, not at the very end. This allows the fused representation to be further processed by the remaining `M` layers of the K-encoder before generating outputs.
4. **Color Coding:** Yellow consistently represents text-related components ("Input Text", T-encoder's "Self-Attention", left side of fusion module). Light blue represents knowledge-graph-related components (Knowledge Graph nodes, K-encoder's right "Self-Attention", right side of fusion module). This visual scheme reinforces the dual-pathway concept.
### Interpretation
This diagram illustrates a sophisticated **multi-modal neural network architecture** designed for tasks that require reasoning over both unstructured text and structured knowledge (e.g., complex question answering, fact-checking, or enhanced document understanding).
* **What it demonstrates:** The model learns a joint representation of text and knowledge. The T-encoder creates a contextualized understanding of the language. The K-encoder's right branch encodes the relational structure of the knowledge graph. The **Text-Knowledge Fusion Module** is the investigative core—it likely uses mechanisms like cross-attention to allow textual concepts to attend to relevant knowledge graph entities and relations, and vice-versa, creating a unified semantic space.
* **Relationship between elements:** The flow is hierarchical and integrative. Raw inputs are first refined in isolation (T-encoder for text, initial KG encoding), then brought together in a dedicated fusion module within a deeper encoder (K-encoder), and finally projected into task-specific output spaces. This suggests the fused representation is rich enough to support multiple downstream applications.
* **Notable implications:** The separate "Knowledge Graph Outputs" imply the model can perform tasks directly on the graph structure (like link prediction or graph classification) using the infused textual context. The architecture explicitly avoids simply appending knowledge graph embeddings to text embeddings; instead, it promotes deep, layer-wise interaction between the two modalities, which is key for sophisticated reasoning. The variable `N` and `M` layers offer flexibility to tune the model's capacity for each sub-task.
DECODING INTELLIGENCE...