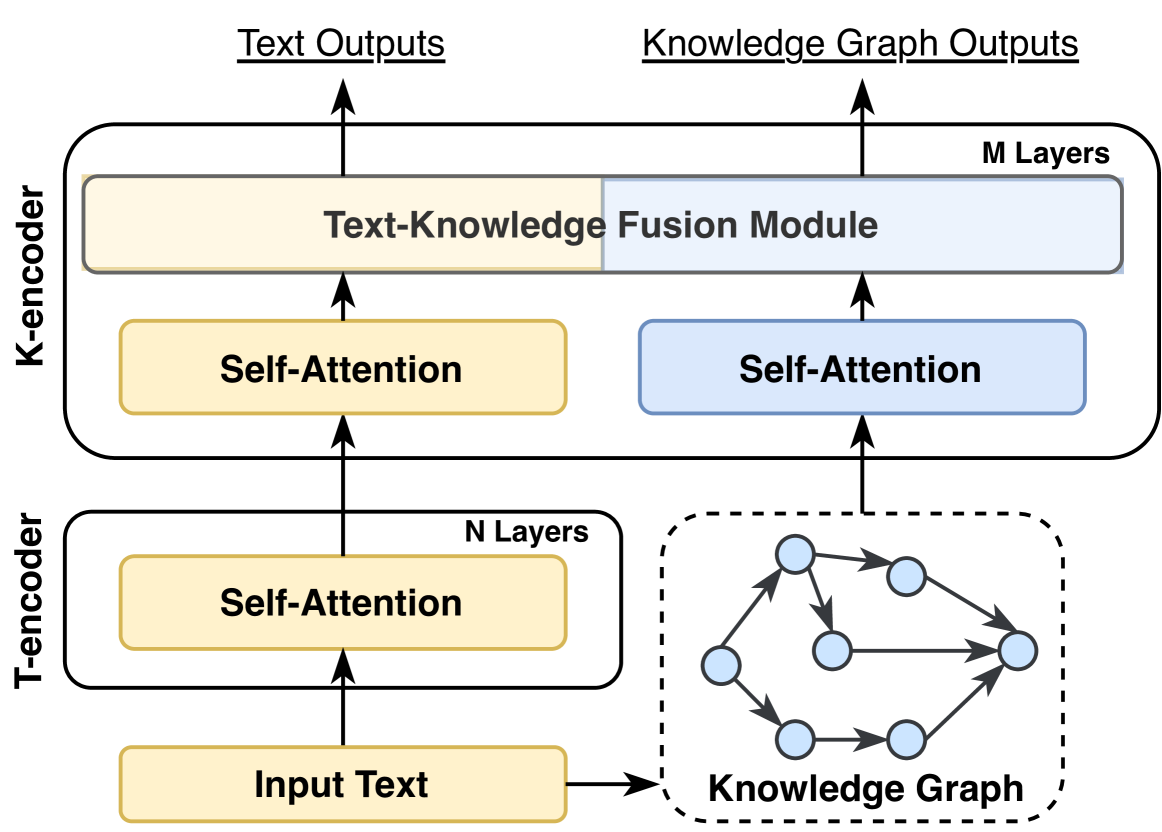
## Diagram: Neural Architecture for Text-Knowledge Fusion
### Overview
The diagram illustrates a neural architecture combining text encoding, self-attention mechanisms, and knowledge graph integration. It shows two encoders (K-Encoder and T-Encoder), a fusion module, and a knowledge graph, with directional flow indicated by arrows.
### Components/Axes
- **K-Encoder**: Yellow block with "Self-Attention" and "Text-Knowledge Fusion Module" subcomponents.
- **T-Encoder**: White block with "Self-Attention" and "N Layers" subcomponents.
- **Knowledge Graph**: Gray dashed box with interconnected nodes (6 nodes, 9 edges).
- **Fusion Module**: Blue block labeled "M Layers" receiving inputs from both encoders.
- **Outputs**:
- Text Outputs (top arrow from fusion module)
- Knowledge Graph Outputs (right arrow from fusion module)
- **Input**: "Input Text" feeding into T-Encoder.
### Detailed Analysis
1. **K-Encoder**:
- Contains a "Self-Attention" layer.
- Outputs to the "Text-Knowledge Fusion Module."
2. **T-Encoder**:
- Composed of "N Layers" of self-attention.
- Outputs to the fusion module.
3. **Knowledge Graph**:
- Represented as a directed graph with 6 nodes and 9 edges.
- Connected to the fusion module via dashed lines.
4. **Fusion Module**:
- Contains "M Layers" of processing.
- Integrates inputs from K-Encoder and T-Encoder.
- Produces dual outputs: text and knowledge graph.
### Key Observations
- **Color Coding**:
- Yellow (K-Encoder), White (T-Encoder), Blue (Fusion Module), Gray (Knowledge Graph).
- **Flow Direction**:
- Input → T-Encoder → Knowledge Graph → Fusion Module → Outputs.
- Input → K-Encoder → Fusion Module → Outputs.
- **Layer Depth**:
- T-Encoder has "N Layers" (unspecified number).
- Fusion Module has "M Layers" (unspecified number).
### Interpretation
This architecture suggests a hybrid model for text generation enhanced by knowledge graphs. The K-Encoder and T-Encoder process input text through self-attention mechanisms, while the knowledge graph provides structured external data. The fusion module combines these streams, enabling the system to generate text informed by both linguistic patterns and structured knowledge. The use of "N" and "M" layers implies modular scalability, allowing adjustments to model complexity. The bidirectional flow between text and knowledge graph components indicates a dynamic interaction, potentially improving contextual relevance in outputs.