\n
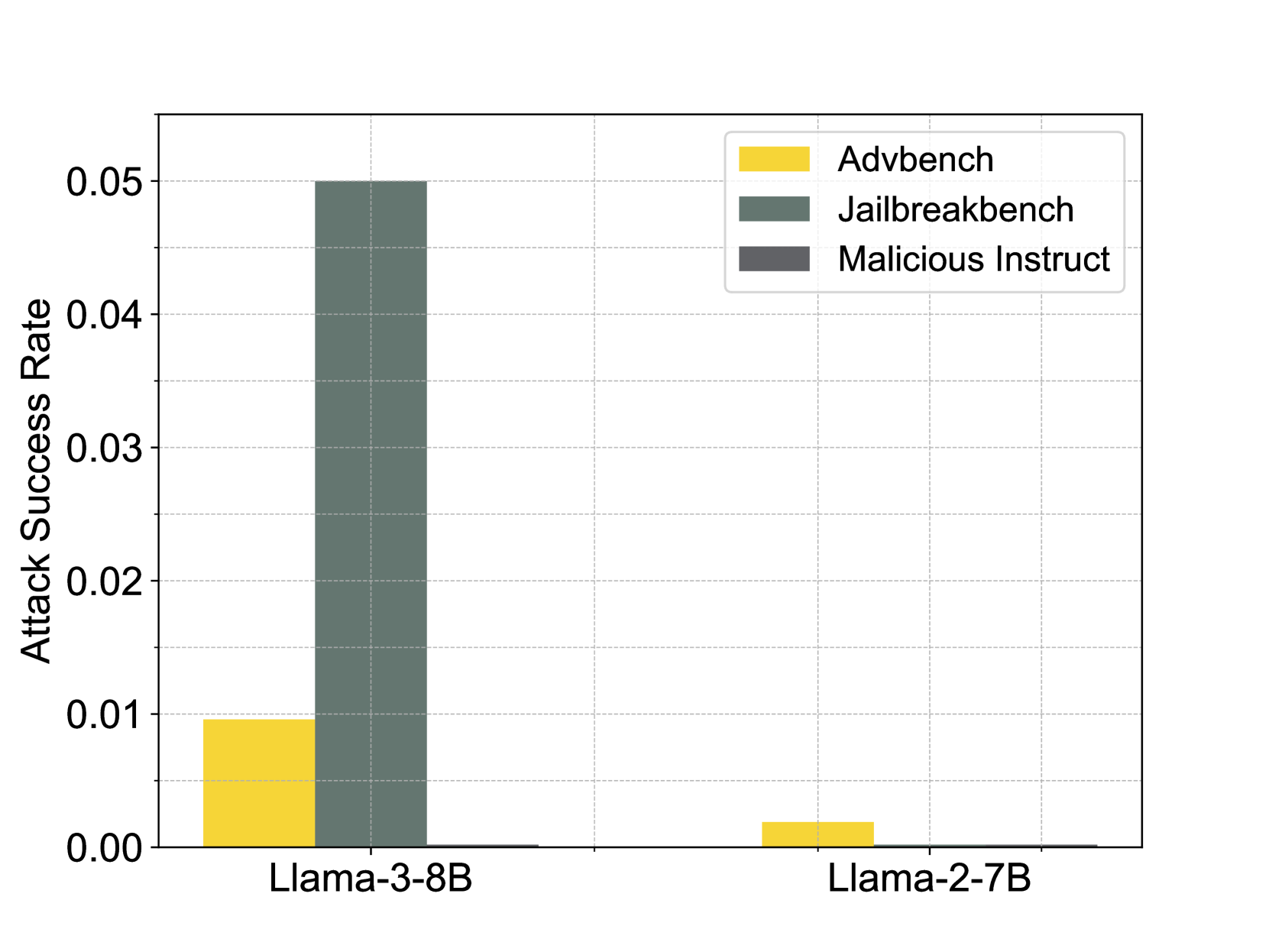
## Bar Chart: Attack Success Rate Comparison
### Overview
This bar chart compares the attack success rates of three different attack types (Advbench, Jailbreakbench, and Malicious Instruct) against two language models (Llama-3-8B and Llama-2-7B). The y-axis represents the attack success rate, while the x-axis represents the language model. Each attack type is represented by a different color bar.
### Components/Axes
* **X-axis:** Language Model - Llama-3-8B, Llama-2-7B
* **Y-axis:** Attack Success Rate - Scale ranges from 0.00 to 0.05, with increments of 0.01.
* **Legend:** Located in the top-right corner.
* Advbench - Yellow
* Jailbreakbench - Gray
* Malicious Instruct - Dark Gray
### Detailed Analysis
The chart consists of six bars, two for each language model, representing the three attack types.
**Llama-3-8B:**
* **Advbench:** The yellow bar for Llama-3-8B starts at approximately 0.008 and extends to approximately 0.01.
* **Jailbreakbench:** The gray bar for Llama-3-8B starts at approximately 0.018 and extends to approximately 0.048.
* **Malicious Instruct:** The dark gray bar for Llama-3-8B starts at approximately 0.015 and extends to approximately 0.045.
**Llama-2-7B:**
* **Advbench:** The yellow bar for Llama-2-7B starts at approximately 0.002 and extends to approximately 0.006.
* **Jailbreakbench:** The gray bar for Llama-2-7B starts at approximately 0.001 and extends to approximately 0.004.
* **Malicious Instruct:** The dark gray bar for Llama-2-7B starts at approximately 0.001 and extends to approximately 0.003.
### Key Observations
* The Jailbreakbench and Malicious Instruct attacks have significantly higher success rates against Llama-3-8B compared to Llama-2-7B.
* Advbench has a relatively low success rate for both models, but is slightly higher for Llama-3-8B.
* Llama-3-8B is more vulnerable to all three attack types than Llama-2-7B.
* The success rates for Jailbreakbench and Malicious Instruct are of similar magnitude for Llama-3-8B.
### Interpretation
The data suggests that Llama-3-8B is more susceptible to adversarial attacks, particularly jailbreaking and malicious instruction attacks, than Llama-2-7B. This could be due to differences in the model architectures, training data, or safety mechanisms implemented in each model. The higher success rates of Jailbreakbench and Malicious Instruct attacks indicate that these models may be more easily manipulated into generating harmful or unintended outputs. The relatively low success rate of Advbench suggests that Llama-3-8B and Llama-2-7B are more robust against attacks that rely on subtle perturbations of the input. The consistent pattern of higher attack success rates for Llama-3-8B across all attack types suggests a systemic vulnerability, rather than a specific weakness to a particular attack strategy. This information is crucial for developers and security researchers to understand the potential risks associated with these language models and to develop effective mitigation strategies.