## Grouped Bar Chart: Attack Success Rates by Model and Benchmark
### Overview
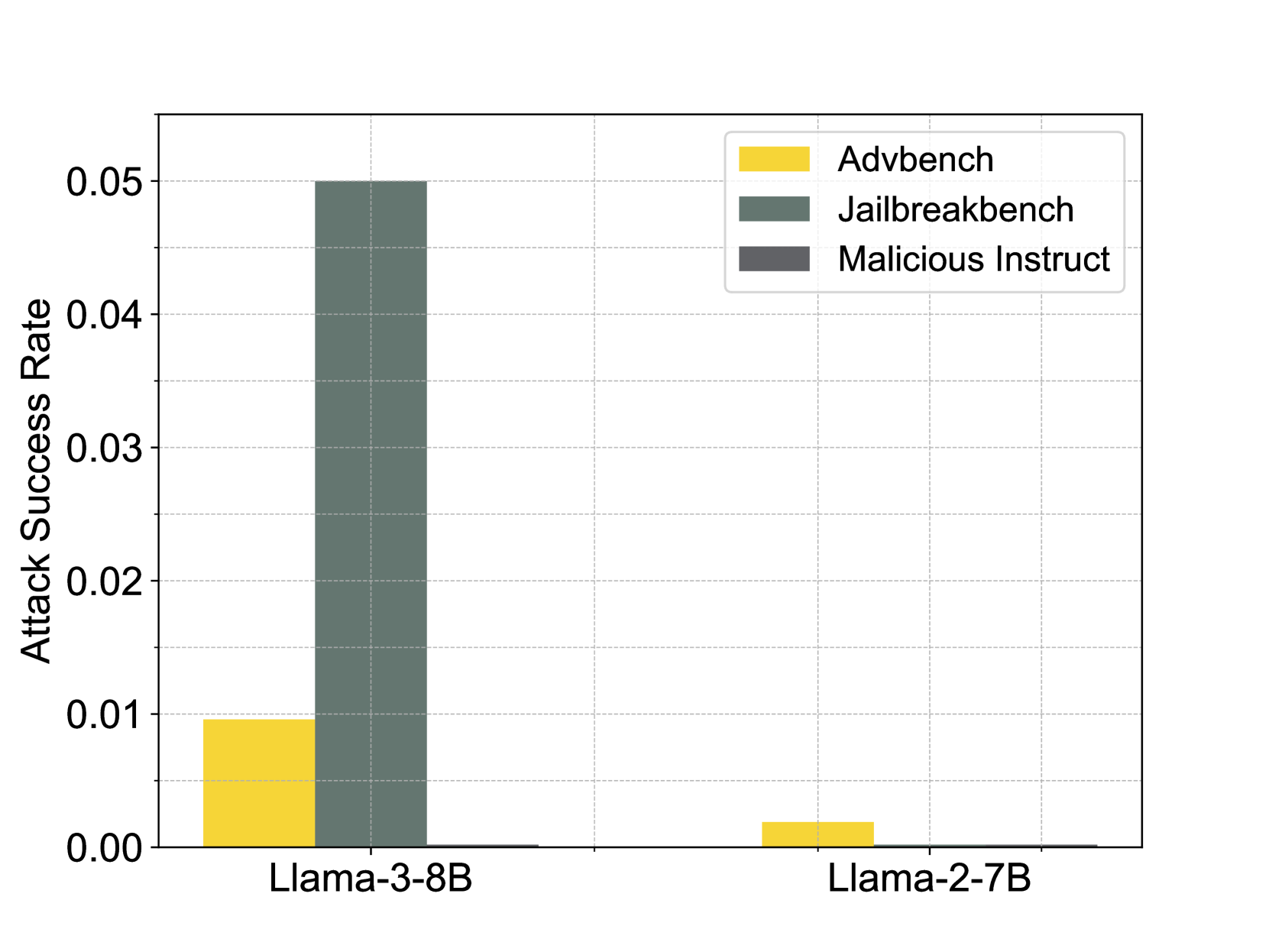
This image is a grouped bar chart comparing the "Attack Success Rate" of two large language models (LLMs) across three different adversarial benchmarks. The chart visually demonstrates a significant disparity in vulnerability between the two models, with one model showing a notably higher success rate for one specific benchmark.
### Components/Axes
* **Chart Type:** Grouped Bar Chart.
* **Y-Axis:**
* **Label:** "Attack Success Rate"
* **Scale:** Linear, ranging from 0.00 to 0.05.
* **Major Ticks:** 0.00, 0.01, 0.02, 0.03, 0.04, 0.05.
* **X-Axis:**
* **Categories (Models):** "Llama-3-8B" (left group), "Llama-2-7B" (right group).
* **Legend:**
* **Position:** Top-right corner of the chart area.
* **Items:**
1. **Advbench:** Represented by a yellow/gold bar.
2. **Jailbreakbench:** Represented by a dark green/teal bar.
3. **Malicious Instruct:** Represented by a dark grey bar.
* **Grid:** Light grey horizontal grid lines are present at each major Y-axis tick.
### Detailed Analysis
**1. Model: Llama-3-8B (Left Group)**
* **Advbench (Yellow Bar):** The bar reaches a height of approximately **0.01** on the Y-axis.
* **Jailbreakbench (Dark Green Bar):** This is the tallest bar in the entire chart. It reaches the top of the scale at **0.05**.
* **Malicious Instruct (Dark Grey Bar):** The bar is extremely short, appearing to be at or very near **0.00**.
**2. Model: Llama-2-7B (Right Group)**
* **Advbench (Yellow Bar):** The bar is very short, with an approximate value of **0.002** (visually estimated as about 1/5th the height of the Llama-3-8B Advbench bar).
* **Jailbreakbench (Dark Green Bar):** The bar is not visible, indicating a value of **0.00** or negligibly close to it.
* **Malicious Instruct (Dark Grey Bar):** The bar is not visible, indicating a value of **0.00** or negligibly close to it.
### Key Observations
1. **Dominant Vulnerability:** The most striking feature is the high attack success rate (0.05) of the **Jailbreakbench** benchmark against the **Llama-3-8B** model. This single data point is five times higher than the next highest value.
2. **Model Disparity:** There is a stark contrast between the two models. **Llama-3-8B** shows measurable vulnerability to two benchmarks (Advbench and Jailbreakbench), while **Llama-2-7B** shows only a minimal, near-zero success rate for Advbench and none for the others.
3. **Benchmark Performance:** **Jailbreakbench** appears to be the most effective attack suite against Llama-3-8B in this test. **Malicious Instruct** shows no measurable success against either model.
4. **Scale Context:** All success rates are low in absolute terms (≤ 5%), but the relative difference between the models and benchmarks is significant.
### Interpretation
This chart presents a comparative security evaluation of two LLMs. The data suggests that the **Llama-3-8B model is significantly more susceptible to the "Jailbreakbench" adversarial attacks** than the Llama-2-7B model under the tested conditions. The near-zero results for "Malicious Instruct" against both models could indicate either robust defenses against that specific attack type or that the benchmark was not effective in this experimental setup.
The stark difference between the two models' performance, especially on Jailbreakbench, raises questions about potential trade-offs between model capability/version and safety guardrails. It implies that the safeguards in Llama-3-8B may be more easily circumvented by certain jailbreaking techniques compared to its predecessor, Llama-2-7B. However, without knowing the specific parameters of the attack methodologies or the exact testing protocol, this remains a preliminary observation. The chart effectively highlights that attack success is highly dependent on both the model architecture and the specific adversarial strategy employed.