## Bar Chart: Attack Success Rates for Llama-3-8B and Llama-2-7B Models
### Overview
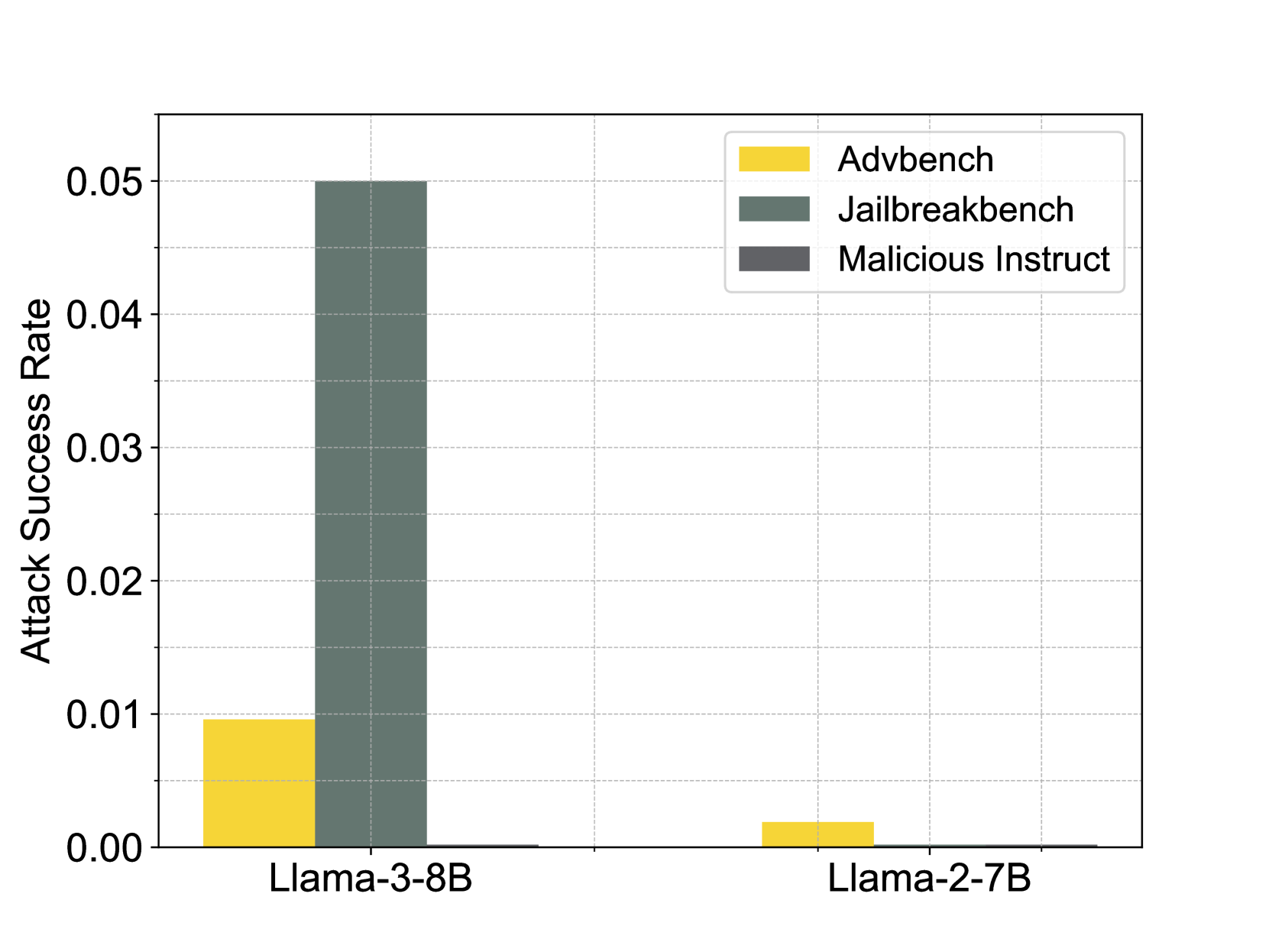
The chart compares attack success rates for two language models (Llama-3-8B and Llama-2-7B) across three attack types: Advbench, Jailbreakbench, and Malicious Instruct. The y-axis represents attack success rate (0.00–0.05), while the x-axis categorizes results by model. Bars are color-coded by attack type, with a legend on the right.
### Components/Axes
- **X-axis**: Model names (Llama-3-8B, Llama-2-7B)
- **Y-axis**: Attack Success Rate (0.00–0.05, increments of 0.01)
- **Legend**:
- Yellow: Advbench
- Green: Jailbreakbench
- Gray: Malicious Instruct
- **Bar Colors**:
- Llama-3-8B: Yellow (Advbench), Green (Jailbreakbench), Gray (Malicious Instruct)
- Llama-2-7B: Yellow (Advbench), Green (Jailbreakbench), Gray (Malicious Instruct)
### Detailed Analysis
1. **Llama-3-8B**:
- **Advbench**: Approximately 0.01 (0.009–0.011)
- **Jailbreakbench**: Approximately 0.05 (0.048–0.052)
- **Malicious Instruct**: Near 0 (0.000–0.001)
2. **Llama-2-7B**:
- **Advbench**: Approximately 0.002 (0.001–0.003)
- **Jailbreakbench**: Near 0 (0.000–0.001)
- **Malicious Instruct**: Near 0 (0.000–0.001)
### Key Observations
- Llama-3-8B demonstrates significantly higher attack success rates across all categories compared to Llama-2-7B.
- Jailbreakbench achieves the highest success rate for Llama-3-8B (0.05), while Malicious Instruct shows negligible effectiveness for both models.
- Llama-2-7B's attack success rates are consistently below 0.003, with Jailbreakbench and Malicious Instruct results indistinguishable from zero.
### Interpretation
The data suggests Llama-3-8B is substantially more vulnerable to adversarial attacks, particularly Jailbreakbench, which achieves near-maximum success. The negligible Malicious Instruct results for both models indicate this attack type is ineffective against these architectures. Llama-2-7B's lower performance across all categories implies better robustness, though its Advbench success (0.002) remains non-trivial. The stark contrast between Llama-3-8B's Jailbreakbench success (0.05) and Llama-2-7B's near-zero result highlights architectural differences in security hardening. This chart underscores the importance of model-specific security evaluations, as larger models (Llama-3-8B) may inherit greater vulnerabilities despite increased capability.