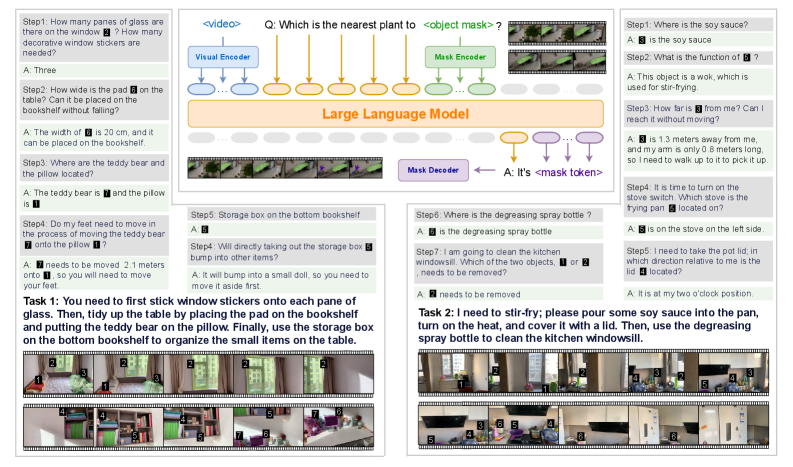
## Diagram: Visual Question Answering System
### Overview
The image presents a diagram illustrating a visual question answering (VQA) system. It outlines two tasks, each involving a series of steps and questions, processed by a large language model (LLM) with visual and mask encoders/decoders. The diagram shows the flow of information and the interaction between the model and visual inputs.
### Components/Axes
* **Header:** Contains the title "Q: Which is the nearest plant to <object mask>?" and the label "<video>".
* **Visual Encoder:** Processes video input.
* **Mask Encoder:** Processes object masks.
* **Large Language Model:** The central processing unit.
* **Mask Decoder:** Generates mask tokens.
* **Task 1:** Involves sticking window stickers, tidying the table, and organizing items on a bookshelf.
* **Task 2:** Involves stir-frying and cleaning the kitchen windowsill.
* **Steps:** Each task is broken down into numbered steps (Step 1, Step 2, etc.).
* **Questions (Q):** Each step poses a question.
* **Answers (A):** Each question has a corresponding answer.
* **Visual Input:** Each step is accompanied by a series of images representing the scene.
* **Arrows:** Indicate the flow of information between components.
### Detailed Analysis or Content Details
**Task 1:**
* **Step 1:**
* Q: How many panes of glass are there on the window? How many decorative window stickers are needed?
* A: Three
* Visual Input: Images showing a window with panes.
* **Step 2:**
* Q: How wide is the pad on the table? Can it be placed on the bookshelf without falling?
* A: The width of 6 is 20 cm, and it can be placed on the bookshelf.
* Visual Input: Images showing a pad on a table.
* **Step 3:**
* Q: Where are the teddy bear and the pillow located?
* A: The teddy bear is 7 and the pillow is 1.
* Visual Input: Images showing a teddy bear and a pillow.
* **Step 4:**
* Q: Do my feet need to move in the process of moving the teddy bear 7 onto the pillow 1?
* A: 7 needs to be moved 2.1 meters onto 1, so you will need to move your feet.
* Visual Input: Images showing feet and the teddy bear/pillow.
* **Step 5:**
* Q: Storage box on the bottom bookshelf
* A: 5
* Visual Input: Images showing a storage box on a bookshelf.
* **Step 4 (repeated):**
* Q: Will directly taking out the storage box 5 bump into other items?
* A: It will bump into a small doll, so you need to move it aside first.
* Visual Input: Images showing the storage box and other items.
**Task 2:**
* **Step 1:**
* Q: Where is the soy sauce?
* A: 3 is the soy sauce
* Visual Input: Images showing soy sauce.
* **Step 2:**
* Q: What is the function of 6?
* A: This object is a wok, which is used for stir-frying.
* Visual Input: Images showing a wok.
* **Step 3:**
* Q: How far is 3 from me? Can I reach it without moving?
* A: 3 is 1.3 meters away from me, and my arm is only 0.8 meters long, so I need to walk up to it to pick it up.
* Visual Input: Images showing the distance to an object.
* **Step 4:**
* Q: It is time to turn on the stove switch. Which stove is the frying pan 5 located on?
* A: 5 is on the stove on the left side.
* Visual Input: Images showing a stove and frying pan.
* **Step 5:**
* Q: I need to take the pot lid; in which direction relative to me is the lid 4 located?
* A: It is at my two o'clock position.
* Visual Input: Images showing a pot lid.
* **Step 6:**
* Q: Where is the degreasing spray bottle?
* A: 6 is the degreasing spray bottle
* Visual Input: Images showing a degreasing spray bottle.
* **Step 7:**
* Q: I am going to clean the kitchen windowsill. Which of the two objects, 1 or 2 needs to be removed?
* A: 2 needs to be removed
* Visual Input: Images showing the kitchen windowsill and objects.
**Flow of Information:**
1. The system receives a video input and a question related to an object mask.
2. The Visual Encoder processes the video.
3. The Mask Encoder processes the object mask.
4. The Large Language Model integrates the encoded information.
5. The Mask Decoder generates a mask token.
6. The system provides an answer based on the mask token.
### Key Observations
* The system uses visual and mask encoders to process visual information.
* The Large Language Model is central to the question answering process.
* The tasks involve understanding spatial relationships, object recognition, and following instructions.
* The system provides detailed answers based on the visual input and the questions asked.
### Interpretation
The diagram illustrates a VQA system designed to understand and respond to questions about visual scenes. The system combines visual processing with natural language understanding to perform tasks that require both perception and reasoning. The breakdown of tasks into steps and questions demonstrates a structured approach to problem-solving. The system's ability to provide detailed answers suggests a sophisticated understanding of the visual environment and the relationships between objects within it. The use of object masks allows the system to focus on specific regions of interest, improving accuracy and efficiency.