TECHNICAL ASSET FINGERPRINT
39c82045699828082cd4cea2
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
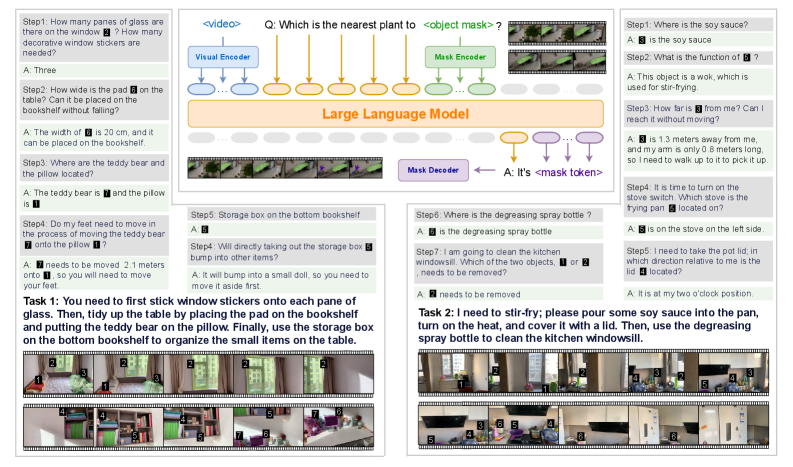
## System Architecture Diagram: Multimodal AI for Embodied Task Execution
### Overview
The image is a technical diagram illustrating a multimodal AI system designed to process visual information and natural language instructions to perform embodied tasks (e.g., organizing a room, cooking). It combines a central model architecture with two concrete task examples, showing the flow from visual input to action planning.
### Components/Axes
The diagram is divided into three main regions:
1. **Central Architecture Flow (Top Center):** Shows the core model pipeline.
* **Input:** A video sequence (represented by a filmstrip icon labeled `<video>`).
* **Encoders:** Two parallel encoders process the input:
* `Visual Encoder` (blue box)
* `Mask Encoder` (green box)
* **Core Model:** Both encoders feed into a `Large Language Model` (large orange box).
* **Output:** The LLM connects to a `Mask Decoder` (purple box), which produces an answer: `A: It's <mask token>`.
* **Query:** A question is posed to the system: `Q: Which is the nearest plant to <object mask>?`
2. **Task 1 Example (Left Panel):** "You need to first stick window stickers on each pane of glass. Then, tidy up the table by placing the pad on the bookshelf and putting the teddy bear on the pillow. Finally, use the storage box on the bottom bookshelf to organize the small items on the table."
* Contains 7 numbered steps (Step1 to Step7), each with a question (`Q:`) and an answer (`A:`).
* Includes a sequence of 8 small images at the bottom, showing a simulated environment (a room with furniture) and the progression of the task.
3. **Task 2 Example (Right Panel):** "I need to stir-fry; please pour some soy sauce into the pan, turn on the heat, and cover it with a lid. Then, use the degreasing spray bottle to clean the kitchen windowsill."
* Contains 5 numbered steps (Step1 to Step5), each with a question (`Q:`) and an answer (`A:`).
* Includes a sequence of 8 small images at the bottom, showing a simulated kitchen environment and the progression of the task.
### Detailed Analysis
**Central Architecture:**
* The system takes a video as input.
* It uses a dual-encoder setup: a `Visual Encoder` likely processes raw visual features, while a `Mask Encoder` likely processes segmentation or object mask information.
* These encoded features are processed by a `Large Language Model` (LLM), suggesting the model uses language modeling capabilities to reason about the visual data.
* The final output is generated by a `Mask Decoder`, producing a `<mask token>`, indicating the system identifies or localizes objects (like the "nearest plant") within the visual scene.
**Task 1 (Organizing a Room) - Step-by-Step Transcription:**
* **Step1:** Q: How many panes of glass are there on the window? How many decorative window stickers are needed? A: Three.
* **Step2:** Q: How wide is the pad on the table? Can it be placed on the bookshelf without falling? A: The width of [pad icon] is 20 cm, and it can be placed on the bookshelf.
* **Step3:** Q: Where are the teddy bear and the pillow located? A: The teddy bear is [teddy icon] and the pillow is [pillow icon].
* **Step4:** Q: Do my feet need to move in order to put the teddy bear onto the pillow? A: [teddy icon] needs to be moved 2.1 meters away, so you will need to move your feet.
* **Step5:** Q: Storage box on the bottom bookshelf. A: [box icon].
* **Step6:** Q: Will directly taking out the storage box bump into other items? A: It will bump into a small doll, so you need to move it aside first.
* **Step7:** Q: Where is the degreasing spray bottle? A: [spray bottle icon] is the degreasing spray bottle.
* **Step8:** Q: I am going to clean the kitchen windowsill. Which of the two objects, [pad icon] or [teddy icon], needs to be removed? A: [teddy icon] needs to be removed.
**Task 2 (Cooking & Cleaning) - Step-by-Step Transcription:**
* **Step1:** Q: Where is the soy sauce? A: [soy sauce icon] is the soy sauce.
* **Step2:** Q: What is the function of [wok icon]? A: This object is a wok, which is used for stir-frying.
* **Step3:** Q: How far is [wok icon] from me? Can I reach it without moving? A: [wok icon] is 1.3 meters away from me, and my arm is only 0.8 meters long, so I need to walk up to it to pick it up.
* **Step4:** Q: It is time to turn on the stove switch. Which stove is [wok icon] located on? A: [wok icon] is on the stove on the left side.
* **Step5:** Q: I need to take the pot lid. In which direction relative to me is the [lid icon] located? A: It is at my two o'clock position.
### Key Observations
1. **Multimodal Integration:** The architecture explicitly combines visual data (video) with mask/segmentation data before processing with an LLM, indicating a sophisticated approach to visual reasoning.
2. **Embodied Reasoning:** The tasks require spatial understanding ("2.1 meters away," "two o'clock position"), object affordances ("used for stir-frying"), and sequential planning.
3. **Interactive Dialogue:** The system engages in a question-answer format to clarify steps and gather necessary information before acting, mimicking human-in-the-loop or interactive agent behavior.
4. **Visual Grounding:** The answers frequently reference specific icons (e.g., [pad icon], [wok icon]), showing the system's ability to ground language in visual objects within the scene.
5. **Task Complexity:** The tasks progress from simple identification (Step1 in both) to complex spatial reasoning and action sequencing (e.g., moving an obstacle before retrieving an item).
### Interpretation
This diagram presents a framework for an AI agent that can perceive a dynamic environment (via video), understand natural language instructions, and reason about objects, their properties, and spatial relationships to plan and execute multi-step physical tasks. The central model architecture suggests a method where visual and mask-based features are fused and processed by a language model to generate actionable insights or answers. The two task examples serve as proof-of-concept demonstrations, highlighting capabilities in:
* **Object Recognition & Localization:** Identifying objects and their attributes (size, location).
* **Spatial & Physical Reasoning:** Calculating distances, reachability, and potential collisions.
* **Sequential Task Planning:** Breaking down a high-level goal into ordered, executable sub-tasks.
* **Interactive Problem-Solving:** Asking clarifying questions to resolve ambiguities in the environment or instructions.
The system appears designed for applications in robotics, augmented reality, or intelligent assistants where an AI must interact with the physical world based on visual and verbal cues. The use of a `<mask token>` output is particularly notable, implying the model can generate segmentation masks or point to specific image regions as part of its response.
DECODING INTELLIGENCE...